




Utiliser des données administratives dans le cadre d’une évaluation aléatoire
Summary
Les données administratives sont des informations collectées, utilisées et stockées à des fins principalement administratives (c’est-à-dire opérationnelles), et non à des fins de recherche. Ces données constituent une excellente source d’information pour la recherche et les évaluations d’impact. Ce document contient des conseils pratiques sur l’obtention des données administratives non publiques et leur utilisation dans le cadre d’une évaluation aléatoire. Bien qu’une grande partie des concepts abordés dans ce guide soit pertinents dans tous les pays et tous les contextes, certaines sections s’appliquent exclusivement aux recherches menées aux États-Unis.
Introduction
Ce guide contient des conseils pratiques sur les modalités d’obtention des données administratives non publiques et leur utilisation dans le cadre d’une évaluation aléatoire. Les données administratives sont des informations collectées, utilisées et stockées à des fins principalement administratives (c’est-à-dire opérationnelles), et non à des fins de recherche.1 Les ministères et autres institutions collectent des données administratives à des fins d’inscription, de transaction et de tenue de dossiers, généralement dans le cadre de la prestation d’un service. Parmi les exemples de données administratives, on peut citer les transactions effectuées par carte de crédit, les registres de ventes, les dossiers médicaux électroniques, les déclarations de sinistre auprès des compagnies d’assurance, les dossiers scolaires, les registres d’arrestation ou encore les registres de mortalité. Le présent guide se concentre sur les données administratives non publiques (c’est-à-dire les données exclusives ou confidentielles) qui peuvent être utilisées dans le cadre d’une évaluation aléatoire à randomisation individuelle.
Contexte de ce guide
Une grande partie des concepts évoqués dans ce guide s’appliquent à tous les pays et à tous les contextes. Toutefois, les sections relatives aux exigences de conformité (en particulier la loi HIPAA et les exigences spécifiques en matière d’éthique) ne sont directement applicables qu’aux États-Unis. D’autres juridictions présentant un contexte réglementaire similaire peuvent disposer d’une législation comparable (comme le règlement général sur la protection des données de l’Union européenne), ce qui donne à ces concepts une portée plus générale.
Ce guide porte sur les sujets suivants :
- Les procédures standard d’accès aux données administratives
- Le cadre éthique et juridique qui régit l’utilisation de ces données dans le cadre d’une évaluation aléatoire
- Les problèmes les plus courants liés à l’utilisation de données administratives
Pourquoi utiliser des données administratives ?
L’utilisation de données administratives à des fins de recherche présente un certain nombre d’avantages :2
- Coût et facilité. Utiliser des données administratives est souvent moins coûteux et logistiquement plus simple que de collecter de nouvelles données. En effet, contrairement à la collecte de données primaires, la collecte de données administratives ne nécessite pas l’élaboration et la validation d’un instrument d’enquête, le recrutement d’un organisme d’enquête ou d’enquêteurs, ni le suivi des participants en vue des vagues suivantes de l’enquête.3
- Allègement des contraintes imposées aux participants. Les sujets n’ont pas besoin de fournir aux chercheurs des informations qu’ils ont déjà communiquées dans d’autres contextes.
- Couverture quasi-universelle. De nombreuses bases de données administratives existantes sont susceptibles d’inclure la quasi-totalité des personnes concernées par une étude donnée. Les sujets traités et les sujets témoins sont souvent représentés à part égale dans ces données, de même que les sujets qui sont moins susceptibles de répondre aux enquêtes de suivi pour des raisons liées à leur statut de traitement.
- Précision. Les données administratives sont parfois plus précises que les enquêtes lorsqu’il s’agit de mesurer des caractéristiques complexes ou des informations dont les sujets ont du mal à se souvenir (comme les revenus ou la consommation).4
« Pour illustrer l’intérêt des données administratives par rapport aux données d’enquête, on peut citer l’étude de l’Oregon Health Insurance Experiment sur l’impact de la prise en charge par Medicaid des adultes à faible revenu n’ayant pas d’assurance maladie sur la fréquentation des urgences. Cette évaluation aléatoire n’a détecté aucun impact statistiquement significatif sur la fréquentation des urgences sur la base des données d’enquête, mais une augmentation statistiquement significative de 40 % de la fréquentation des urgences sur la base des données administratives (Taubman, Allen, Wright, Baicker, & Finkelstein 2014). Cette différence s’explique en partie par la plus grande précision des données administratives par rapport aux données d’enquête : en se concentrant sur les mêmes périodes et le même ensemble d’individus, les effets estimés étaient plus importants et plus précis dans les données administratives » (Finkelstein & Taubman, 2015).
- Minimisation des biais. L’utilisation de données administratives recueillies de manière passive, plutôt qu’activement déclarées par les individus ou le personnel du programme, minimise le risque de biais de désirabilité sociale ou d’effet enquêteur.
- Disponibilité à long terme. Les données administratives peuvent être collectées de façon systématique et régulière au fil du temps, ce qui permet aux chercheurs d’observer les variables de résultat des participants sur de longues périodes. Ces résultats à long terme sont souvent les plus intéressants du point de vue de la recherche et des politiques publiques, et peuvent permettre aux chercheurs d’identifier des impacts qui ne se manifestent pas à court terme. On en trouve un exemple dans Ludwig et al. (2013) :
Le projet Moving to Opportunity (MTO) consistait à évaluer l’impact de la distribution de bons de logement à des familles vivant dans des quartiers très pauvres. En utilisant des données administratives issues des déclarations d’impôts, les chercheurs ont constaté que les enfants qui avaient moins de 13 ans lorsque leur famille a déménagé dans un quartier moins défavorisé étaient plus nombreux à faire des études supérieures, avaient des revenus plus élevés et vivaient dans des quartiers moins défavorisés à un stade ultérieur de leur vie. Or, lorsque les revenus des adultes sont plus élevés, le montant des impôts dont ils s’acquittent est nettement plus important, ce qui, à long terme, peut permettre aux pouvoirs publics de faire des économies. Ces effets à long terme sont donc précieux pour évaluer l’impact potentiel des bons de logement sur la lutte contre la pauvreté, mais ils n’étaient pas visibles dans les données à court terme.
- Données sur les coûts. Certaines sources de données administratives font autorité en matière de données sur les coûts, et permettent de mener des recherches sur les finances publiques ou de réaliser des analyses coût-efficacité. Par exemple, les demandes de remboursement au titre de Medicare indiquent le coût exact pour le contribuable des soins de santé couverts par Medicare.
Vous trouverez d’autres exemples d’utilisation des données administratives dans la note de synthèse intitulée « Lessons of Administrative Data », publiée par J-PAL Amérique du Nord.
Les données administratives présentent également des limites, des défis et des risques, qui sont décrits plus en détail dans la section suivante sur les « Biais potentiels ». L’étude de l’Oregon comme celle du MTO ont exploité à la fois des données administratives et des données d’enquête, ce qui a permis aux chercheurs d’étudier un large éventail de variables de résultat et d’individus.5
Biais potentiels
Si les données administratives sont plus précises et moins sujettes à certains biais que les données d’enquête (Finkelstein et Taubman 2015; Meyer et Mittag 2015), elles ne sont pas pour autant à l’abri des problèmes de biais et d’imprécision. Dans le cas des données administratives, les biais sont particulièrement problématiques si le fait d’être assigné au groupe de traitement affecte la probabilité qu’un individu apparaisse dans les données ou que l’on puisse le rattacher à son dossier dans ces dernières.
Couverture différentielle : l’observabilité dans les données administratives
Les problèmes de couverture différentielle, c’est-à-dire la différence entre le type ou la proportion de données manquantes chez les sujets traités et les sujets témoins, peuvent également se manifester lorsqu’on utilise des données administratives. Un tel problème survient lorsque les membres du groupe de traitement et du groupe témoin n’ont pas la même probabilité d’apparaître dans les dossiers administratifs, ou lorsque les chercheurs n’ont pas la même probabilité de pouvoir faire le lien entre les individus et leur dossier administratif. Dans ce cas, les chercheurs ne peuvent pas avoir la certitude que le groupe de traitement et le groupe témoin sont statistiquement équivalents, et les estimations d’impact basées sur ces données peuvent donc être biaisées. Dans de telles situations, il convient d’être particulièrement attentif à la façon dont on traite les données manquantes ou non appariées. Tenter de corriger ces problèmes peut s’avérer problématique, car il est possible que le profil des individus manquants dans chaque groupe diffère de manière inobservable.
Lorsqu’on utilise des données administratives, les problèmes de couverture différentielle peuvent prendre les formes suivantes :
- On utilise les identifiants obtenus au moment de l’inscription ou de l’enquête initiale pour faire le lien entre les individus et leurs données administratives. Par exemple, les membres du groupe de traitement peuvent être plus disposés à donner leur numéro de sécurité sociale après avoir eu plusieurs interactions avec un membre de l’équipe chargée de l’étude. Les membres du groupe témoin, en revanche, n’ont pas l’occasion d’établir une telle relation de confiance. Par conséquent, les chercheurs ont plus de chances de trouver un dossier administratif pour les membres du groupe de traitement que pour les membres du groupe témoin.
- On utilise des données générées par le programme auquel les participants sont assignés de manière aléatoire. Il est généralement déconseillé d’utiliser les données de processus ou de suivi du programme pour évaluer les effets de l’assignation aléatoire à ce même programme (ou des encouragements à participer à ce même programme). En effet, de par leur statut de traitement, les membres du groupe de traitement ont plus de chances d’apparaître dans les données de mise en œuvre du programme que les membres du groupe témoin. En outre, ces données ne sont probablement pas collectées de la même manière ou avec la même précision pour le groupe de traitement et pour le groupe témoin, ce qui engendre des biais. Prenons l’exemple théorique d’une évaluation dans le cadre de laquelle certaines personnes seraient assignées à recevoir des conseils financiers dans une succursale spécifique d’une coopérative d’épargne et de crédit. En mesurant la santé financière à partir des données de cette même succursale, on obtiendrait probablement une proportion bien plus importante de membres du groupe de traitement, désormais rattachés à cette succursale, que de membres du groupe témoin. Dans ce cas de figure, les chercheurs pourraient se faire une idée bien plus complète de la santé financière en utilisant les données d’une agence nationale d’évaluation du crédit.
- Les membres du groupe de traitement sont plus (ou moins) susceptibles que ceux du groupe témoin de figurer dans une source de données administratives particulière du fait de leur assignation de traitement. Prenons l’exemple théorique suivant :
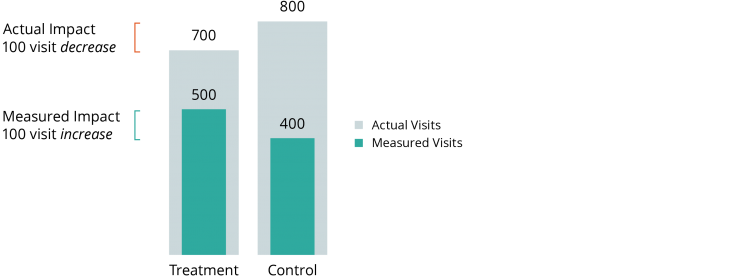
Les chercheurs prévoient de mesurer l’impact d’un programme intensif de soins de santé à domicile sur la fréquence des admissions à l’hôpital en utilisant les données des demandes de remboursement de Medicaid. Or, dans le cadre de ses services habituels, le programme de soins de santé à domicile aide également les participants à souscrire aux prestations sociales auxquelles ils peuvent prétendre, dont Medicaid. En raison de cette assistance offerte par le programme de soins à domicile, les individus du groupe de traitement sont donc plus susceptibles de figurer dans les dossiers Medicaid que les individus du groupe témoin. Comme le montre la figure ci-dessous, même si l’intervention réduit effectivement le nombre d’hospitalisations (qui passe par exemple de 800 à 700 ici), les chercheurs qui analysent les données de Medicaid risquent de constater l’effet inverse (ici une augmentation de 400 à 500) du fait de la plus grande proportion de membres du groupe de traitement qui apparaît dans les données d’hospitalisation.
Biais de déclaration
De nombreuses catégories de données administratives sont collectées de manière passive, au gré des ventes, des commandes ou des transactions. Il arrive toutefois que certains éléments d’un ensemble de données administratives soient activement déclarés par les individus, plutôt que d’être collectés passivement. Par exemple, les antécédents de grossesse et l’historique des soins prénataux qui figurent sur les actes de naissance reposent en grande partie sur les déclarations faites par les mères elles-mêmes. Des études portant sur la validation des données des actes de naissance ont montré que ces données autodéclarées avaient un degré de validité inférieur à celui des informations sur le poids de naissance, le score d'Apgar, l'âge gestationnel et le type d’accouchement, qui sont consignées sur la base des observations et des mesures d’un professionnel (Lee et. al 2015).
Selon l’objectif initial de la collecte des données, l’organisation qui recueille les données peut avoir différentes incitations à vérifier l’exactitude des informations. En outre, l’individu ou l’organisme administratif (ou les deux) peuvent également avoir des incitations à déclarer des données erronées. Un individu peut par exemple être incité à sous-déclarer ses revenus dans le cadre d’une demande d’aide sociale. En ce qui concerne les demandes de remboursement de soins de santé, les procédures coûteuses sont généralement déclarées afin d’obtenir un remboursement, mais certaines procédures moins onéreuses peuvent ne pas l’être si la probabilité d’être remboursé est faible.
Pour évaluer la validité des données administratives, il est essentiel de comprendre comment et pourquoi elles ont été déclarées, collectées et vérifiées. Il est important également de se demander si l’expérimentation elle-même est susceptible d’avoir une incidence sur les incitations relatives à la déclaration et à la validité des données.
Par exemple, des études ont établi un lien entre les examens scolaires à forts enjeux et un certain nombre de stratégies visant à gonfler artificiellement les résultats des tests standardisés. Dans ce cas, les dossiers administratifs des écoles où les résultats ont été fortement majorés risquent de fournir des mesures moins précises de l’apprentissage des élèves qu’une évaluation cognitive indépendante réalisée par un chercheur
Sources de données administratives
Les partenaires de mise en œuvre sont une ressource précieuse pour identifier les sources de données administratives qui sont pertinentes pour votre évaluation. Votre partenaire a peut-être déjà accès à certains types de données dans le cadre de ses activités habituelles, ce qui fournira un point de départ naturel pour les discussions à ce sujet. Par exemple, il est possible qu’un organisme à but non lucratif du secteur de la santé publique ait déjà des partenariats établis avec les agences Medicaid des différents États, susceptibles d’être exploités pour élargir un accord préexistant d’utilisation des données.
En dehors de ce premier canal, J-PAL Amérique du Nord a entrepris de compiler un catalogue des ensembles de données administratives susceptibles d’être utilisés dans le cadre d’évaluations aléatoires, en se concentrant sur les ensembles de données qui ne sont pas destinés à un usage public.
Voici quelques idées et exemples de données administratives dans le contexte des États-Unis :
- Le Research Data Assistance Center (ResDAC), qui fournit des informations et de l’aide pour les demandes d’accès aux données des Centers for Medicare and Medicaid Services.
- Les agences d’évaluation du crédit : Equifax, Experian et TransUnion.
- L'American Economic Association héberge des ressources répertoriant les sources de données administratives fédérales américaines et les procédures d’accès correspondantes.
- Des chercheurs ont dressé un inventaire des ensembles de données utilisés dans les études sur l’éducation.
Coût
Le prix et la structure tarifaire des ensembles de données administratives sont très variables. En effet, les fournisseurs de données peuvent facturer par dossier individuel, par plage de dossiers (par exemple, <10 000 dossiers, 10 000-50 000 dossiers, >50 000 dossiers), par année de dossier, ou sur la base du remboursement des frais engagés (par exemple, en fonction du nombre d’heures de travail consacrées à la préparation des données demandées).
Les chercheurs peuvent parfois profiter du réseau professionnel de leur partenaire dans le secteur des données pour acquérir des données plus rapidement et à un tarif plus avantageux par l’intermédiaire de canaux préexistants. Par exemple, il est possible qu’un organisme à but non lucratif qui offre des services de conseil en matière de crédit bénéficie déjà d’un accès gratuit ou à tarif réduit aux données des rapports de solvabilité pour mener à bien ses activités de conseil en crédit. Les chercheurs peuvent mettre à profit ces relations existantes à la fois pour réduire le prix des données nécessaires à leur évaluation et pour se renseigner sur les procédures de transfert de données utilisées par l’organisme partenaire.
Dans d’autres cas, les chercheurs sont obligés de faire une nouvelle demande de données destinées exclusivement à des fins de recherche. Les prix varient considérablement : à titre d’exemple, les données des listes électorales en Pennsylvanie coûtent 20 dollars par comté ; les données des rapports de solvabilité pour un échantillon de 200 000 à 300 000 individus sur un an coûtent plus de 5 000 dollars ; un an de dossiers Medicare de patients en consultation externe pour l’ensemble de la population bénéficiaire coûte plus de 10 000 dollars. Bien que le coût total semble très élevé, le coût marginal par individu peut être bien inférieur au coût d’une collecte de données primaires. La décision finale doit tenir compte de la taille de l’échantillon, du coût et de la valeur des données administratives disponibles, ainsi que du coût d’une enquête et du taux de réponse attendu.
En raison du coût élevé des données, certains fournisseurs de données (notamment les Centers for Medicare and Medicaid Services) exigent une preuve de financement et une lettre de soutien de l’organisme de financement avant de conclure un accord d’utilisation des données. Pour répondre à ces demandes, le personnel de recherche aura sans doute besoin d’accéder aux informations administratives et financières du chercheur principal qui demande les données.
Les chercheurs doivent également tenir compte du temps nécessaire à la soumission d’une demande de données, et être au courant des démarches (souvent nombreuses) qui peuvent être nécessaires pour obtenir les autorisations requises. Certains jeux de données sont soumis à l’examen d’un comité de protection de la vie privée (qui peut relever de la même procédure que celle de l’IRB ou s’y ajouter). La fréquence et les dates des réunions de ce comité doivent être intégrées dans le calendrier du projet. Des organismes partenaires et/ou des universitaires ayant déjà acquis des données similaires pourront peut-être vous aider en vous expliquant les procédures qu’ils ont dû suivre et, si possible, en mettant en relation l’équipe de recherche avec les fournisseurs de données concernés.
Identifier l’univers de données et le contenu de ces dernières
Lorsqu’on envisage d’utiliser des données administratives, il est essentiel de bien cerner l’univers de données concerné et le contenu de ces données. On commencera naturellement par demander au fournisseur de données un dictionnaire de données, si celui-ci n’est pas disponible en ligne. S’il est vrai que certaines données sont très bien documentées, il n’est pas rare que la documentation soit incomplète, même pour des ensembles de données largement utilisés.
-
Identifiez l’univers dont sont issues les données collectées. Si le fait de figurer dans le jeu de données dépend de l’inscription à un programme ou de la mesure d’une intervention (par exemple, la souscription à une prestation sociale, l’adhésion à une coopérative de crédit), veillez à bien cerner tous les critères d’éligibilité qui s’appliquent. Il s’agit là d’un point essentiel pour identifier les risques de biais potentiels liés à l’utilisation de ce jeu de données, comme nous l’avons vu dans la section précédente consacrée à la couverture différentielle.
Prenons l’exemple de l’univers dont sont issues les données collectées sur la fréquentation des écoles publiques. Les élèves doivent vivre dans le secteur scolaire concerné ou avoir obtenu une dérogation pour être affectés dans une école de ce secteur, et y être inscrits. Le fait de vivre dans le secteur en question peut être corrélé avec les revenus ou la participation aux activités locales. Le fait d’obtenir une dérogation spéciale peut être corrélé avec le niveau d’implication ou de compétence des parents. Le fait d’être scolarisé dans une école publique plutôt que dans une école privée peut être corrélé avec les revenus, les résultats des élèves, la motivation des parents ou l’existence d’un programme de bons éducatifs. Compte tenu de tous ces facteurs, il n’est sans doute pas judicieux d’étudier les résultats scolaires en utilisant les dossiers des écoles publiques si l’intervention est susceptible d’être corrélée avec le fait de rester scolarisé dans ce secteur scolaire ou de s’inscrire dans une école privée.
- Déterminez de quelle manière et pour quelles raisons les données sont enregistrées. Il s’agit par exemple de savoir si les données sont déclarées de manière active par un individu ou si elles sont collectées passivement. Si elles sont déclarées de manière active, vous devez identifier les incitations à déclarer des informations exactes et déterminer s’il existe des incitations à fournir délibérément des informations erronées.
- Identifiez le contenu des données. Même si vous disposez d’un dictionnaire de données décrivant le contenu de l’ensemble de données, cette étape nécessite souvent plusieurs échanges avec le fournisseur afin de clarifier la signification des différents éléments du jeu de données, car le nom ou la description des variables sont parfois ambigus.
- Identifiez les identifiants disponibles. Les identifiants qui figurent dans l’ensemble de données administratives (par exemple le nom, la date de naissance, le numéro de sécurité sociale, le numéro d’identification Medicaid, etc.) varient selon le fournisseur de données, de même que le sous-ensemble de ces identifiants que le fournisseur est prêt à partager. Pour être certains de pouvoir apparier les données de l’étude sur l’assignation du traitement avec les données administratives, les chercheurs doivent vérifier qu’il y a bien des recoupements entre les identifiants auxquels ils ont accès avant l’assignation aléatoire et ceux qui figurent dans les données administratives qu’ils prévoient d’utiliser. Pour plus d’informations, voir le paragraphe « Quels identifiants utiliser pour apparier des ensembles de données », dans la section « Flux de données ».
S’il est essentiel de pouvoir identifier le statut de traitement ou de témoin des individus pour effectuer l’analyse d’une évaluation aléatoire, et si d’autres caractéristiques individuelles peuvent améliorer l’analyse, les chercheurs n’ont pas nécessairement besoin d’avoir directement accès à des informations d’identification personnelle pour mener à bien une telle évaluation. Pour plus d’informations sur ce processus, voir la section « Formuler une demande de données. »
Considérations éthiques
Comme toute évaluation impliquant des sujets humains, les évaluations aléatoires qui utilisent des données administratives doivent être menées dans le respect des principes éthiques de la recherche. Aux États-Unis, les trois principes directeurs sont le respect de la personne, la bienfaisance et la justice. Ils sont inscrits dans la loi dans le cadre de la politique fédérale de protection des sujets humains (ou « Common Rule ») et avaient déjà été formalisés dans le rapport Belmont.
Ces principes sont pris en compte lors de l’examen effectué par les Institutional Review Boards (IRB) et ont des implications pour toutes les formes de recherche, y compris les évaluations qui se limitent à l’utilisation de données administratives. Par exemple, le respect de la personne impose aux chercheurs de déterminer s’il est nécessaire et pertinent de recueillir le consentement éclairé des individus avant d’accéder à leurs dossiers administratifs. Bien que ce ne soit pas toujours nécessaire, cela peut être exigé dans certains cas. Pour plus de détails, voir la section ci-dessous sur la « conformité » et l’annexe sur le « consentement éclairé ». La bienfaisance impose en outre aux chercheurs de minimiser les inconvénients potentiels de la recherche, ce qui inclut notamment le risque de violation de la confidentialité.
La Collaborative Institutional Training Initiative (CITI) offre des certifications en matière de protection des sujets humains, et les National Institutes of Health (NIH) proposent un tutoriel en ligne sur la protection des participants humains à la recherche. Ces formations donnent plus d’informations sur les principes éthiques de la recherche, leurs applications concrètes et leurs implications pour la recherche. La plupart des IRB exigent que les chercheurs qui interagissent avec des sujets humains ou qui ont accès à des données d’identification suivent l’une de ces formations.
Conformité
Les études utilisant des données administratives sont très souvent considérées comme des recherches impliquant des sujets humains et sont donc soumises à l’examen de l’Institutional Review Board (IRB) de l’établissement d’origine du chercheur.6 Au-delà du champ de compétence de l’IRB, l’accès, le stockage et l’utilisation des données administratives sont régis par une multitude de lois et de réglementations fédérales américaines, de lois et de réglementations propres aux différents États, ainsi que de restrictions et de procédures mises en place par les établissements, qui se superposent les unes aux autres.
Dans la mesure où les exigences de conformité et la définition des données « d’identification » diffèrent selon le domaine, la source et la région, il est essentiel de solliciter l’aide d’un IRB et d’un conseiller juridique au sein de l’établissement d’origine du chercheur pour faire le tri entre les différentes exigences en matière de conformité et de signalement. Le présent guide se concentre sur le contexte des États-Unis. Les recherches menées dans d’autres pays par des chercheurs basés aux États-Unis ont toutes les chances d’être soumises à une procédure d’examen similaire de la part de l’IRB, selon le mode de financement ou la politique de l’université concernée. Comme pour les recherches menées aux États-Unis, la réglementation locale peut également s’appliquer.
Certains types de données administratives contiennent des informations particulièrement sensibles et sont soumises à des exigences supplémentaires en matière de documentation et de conformité avant de pouvoir être utilisées à des fins de recherche. Certaines de ces exigences sont liées à la protection de la vie privée des individus. Par exemple, aux États-Unis, la plupart des données de santé sont créées ou détenues par des entités soumises à la Règle de confidentialité de la loi HIPAA, qui exige la mise en place d’une documentation et de protections supplémentaires pour les données qui entrent dans son champ d’application. Les données sur l’éducation peuvent quant à elles être soumises au Family Educational Rights and Privacy Act (FERPA), qui impose des règles spéciales pour protéger la confidentialité des dossiers des élèves. Les dossiers de la justice pénale et de la justice des mineurs sont également soumis à des règles particulières, qui peuvent varier selon la circonscription. D’autres exigences encore sont imposées pour protéger des informations commerciales confidentielles, indépendamment des considérations relatives à la vie privée des individus. Par exemple, un assureur peut vouloir préserver la confidentialité de ses taux de remboursement et de ses contrats, tout comme des entreprises peuvent vouloir protéger le secret des affaires. En plus des exigences légales, les fournisseurs de données peuvent également demander aux chercheurs qui souhaitent utiliser leurs données administratives de se soumettre à des restrictions ou à des conditions supplémentaires, en particulier pour toutes les données considérées comme « sensibles », quelle qu’en soit la raison.
Les exigences de conformité pour l’utilisation de données administratives dépendent généralement de la facilité avec laquelle il est possible d’établir un lien entre les données en question et des individus particuliers, ainsi que du degré de sensibilité des données. Le tableau 1 sur les niveaux d’identifiabilité des données donne un aperçu très sommaire des trois principaux « niveaux » d’identifiabilité. C’est au fournisseur de données et à l’IRB que revient la décision finale de déterminer le niveau d’identifiabilité des données et les exigences qui s’appliquent. Les chercheurs sont censés évaluer en toute bonne foi le caractère identifiable des données sur la base de leur expertise en matière d’analyse de données. Limiter au maximum la manipulation de données nominatives par les chercheurs eux-mêmes peut considérablement simplifier la procédure d’accès aux données administratives et leur utilisation. Pour savoir comment éviter tout contact direct avec des données nominatives, sans pour autant renoncer aux données individuelles et à l’assignation de traitement, voir la section « Flux de données » ci-dessous.

Le reste de cette section décrit les autorisations nécessaires et les procédures d’obtention des données pour chacun des trois niveaux d’identifiabilité des données, et fournit des précisions supplémentaires pour les données de santé qui entrent dans le champ d’application de la loi HIPAA.
Dans la mesure où les exigences se recoupent largement, nous recommandons au lecteur d’utiliser les tableaux 1 et 2 pour identifier le niveau qui est susceptible de s’appliquer à son cas spécifique, de consulter les tableaux 3 et 4 pour avoir une vue d’ensemble des exigences, puis de lire la section qui correspond à leur cas pour plus de détails
Données identifiables par la recherche
Les données identifiables par la recherche contiennent suffisamment d’informations identifiantes pour pouvoir être directement associées à une personne spécifique. En général, ce type de données contient des éléments d’identification directe des individus, comme le nom, le numéro de sécurité sociale, l’adresse physique, l’adresse e-mail ou le numéro de téléphone. Cependant, les données qui contiennent une combinaison de plusieurs éléments d’identification (comme la date de naissance, le code postal et le sexe) peuvent être considérées comme « identifiables » même si elles ne contiennent pas de nom, de numéro de sécurité sociale ou d’autre élément unique d’identification directe.
En général, les recherches qui utilisent ce type de données sont soumises à une supervision étroite de l’IRB, doivent faire l’objet d’un accord formel d’utilisation des données (DUA), doivent être encadrées par des mesures strictes de sécurité des données et doivent respecter toutes les exigences supplémentaires qui peuvent s’appliquer, comme celles qui sont imposées par le fournisseur de données ou par les lois fédérales ou des Etats.
Considérations supplémentaires pour les données de santé
Les données de santé identifiables par la recherche qui sont recueillies par certains fournisseurs de données (comme les complémentaires santé, les organismes d’assurance maladie ou les prestataires de soins de santé) sont souvent soumises aux exigences et aux restrictions spécifiques de la Règle de confidentialité de la loi HIPAA (Health Insurance Portability and Accountability Act). Ces données, également connues sous le nom de « données de santé protégées » (Protected Health Information, ou PHI), sont particulièrement sensibles. La communication de ce type de données est soumise à des restrictions rigoureuses et peut présenter des risques importants pour le fournisseur de données, y compris en termes de responsabilité légale. Le tableau 2 présente une liste des types de données qui rendent un ensemble de données « identifiable » au sens de la Règle de confidentialité de l’HIPAA.
Nous recommandons vivement aux chercheurs de vérifier si leur partenaire de mise en œuvre ou le fournisseur de données sont soumis à la loi HIPAA. Certains organismes pensent, à tort, qu’ils relèvent de cette loi, ce qui les oblige à se soumettre à un examen et à des règles inutiles. Pour savoir comment déterminer si un organisme est soumis à la Règle de confidentialité de l’HIPAA (en d’autres termes, s’il s’agit d’une « Entité couverte »), le Département américain de la santé et des services sociaux (HHS) donne une définition des entités couvertes et les Centers for Medicare & Medicaid Services (CMS) proposent un outil sous forme d’organigramme.
Dans la mesure où la Règle de confidentialité de l’HIPAA engage la responsabilité des fournisseurs de données de santé lorsque des données nominatives sont en jeu, ces derniers peuvent se montrer particulièrement prudents concernant les modalités de partage des données qu’ils détiennent et les destinataires d’un tel partage. Du fait de la complexité de la Règle de confidentialité, les fournisseurs de données de santé (et les chercheurs) ont parfois du mal à comprendre les obligations auxquelles ils sont soumis, ce qui les incite à un excès de prudence. Le succès de votre relation de travail avec ces fournisseurs de données repose souvent sur un important capital de confiance et de bonne volonté.
Le HHS met à disposition un guide détaillé des exigences associées aux données de santé identifiables dans le cadre de la recherche et sur les applications de la Règle de confidentialité de l’HIPAA dans le domaine de la recherche. Des ressources sur la loi HIPAA sont également disponibles en bas de cette page.
Ensembles de données limités (HIPAA/santé uniquement)
En vertu de la Règle de confidentialité de la loi HIPAA, les ensembles de données dont sont exclus certains éléments spécifiques, répertoriés dans le tableau 2 sur les niveaux d'identifiabilité des données (HIPAA), sont appelés ensembles de données limités. De manière générale, les ensembles de données limités excluent tous les éléments d’identification directe des personnes répertoriées, de leurs proches, de leurs employeurs et des membres de leur ménage, tels que leur adresse ou leur numéro de sécurité sociale. Ces ensembles de données contiennent toutefois certaines informations qui peuvent être utilisées par d’autres personnes pour déduire l’identité des sujets (comme la date de naissance, le code postal et le sexe).
Par rapport aux recherches qui utilisent des données identifiables, les études qui utilisent des ensembles de données limités peuvent bénéficier d’une procédure simplifiée pour obtenir les données auprès du fournisseur et être soumises à une supervision moins stricte. Cependant, ces données sont tout de même considérées comme des données de santé protégées (PHI) et restent bien plus sensibles que les données désidentifiées.
Si les risques associés à l’utilisation d'ensembles de données limités sont moins importants que pour les données identifiables, les fournisseurs de données restent malgré tout exposés à des risques importants en cas de mauvaise utilisation de ces données. En outre, bien que les restrictions imposées par la Règle de confidentialité de l’HIPAA pour le partage des ensembles de données limités soient moins strictes que pour les données identifiables, la complexité de cette Règle incite parfois les fournisseurs de données de santé à faire preuve d’une prudence excessive.
Données désidentifiées ou accessibles au public
Les données désidentifiées sont des données qui ne contiennent pas suffisamment d’éléments d’identification pour permettre d’établir avec certitude un lien avec des personnes spécifiques. Par rapport aux études qui utilisent des données identifiables, celles qui utilisent des données désidentifiées ont de grandes chances de bénéficier d’une procédure simplifiée d’obtention des données et d’une supervision éthique ou réglementaire réduite au minimum. Le risque plus faible de réidentification associé aux données désidentifiées limite le degré d’exposition des fournisseurs de données lorsqu’ils transmettent des données désidentifiées (en d’autres termes, leur responsabilité juridique). Ces derniers ont donc moins tendance à imposer des restrictions ou des exigences supplémentaires aux demandeurs de données.
Bien qu’il soit souvent nécessaire de faire le lien entre les sujets individuels, leur statut de traitement et les variables de résultat mesurées, il est possible d’obtenir les informations individuelles détaillées dont on a besoin sans avoir accès aux éléments d’identification. On peut pour cela demander à un tiers autre que le chercheur (par exemple, le fournisseur de données ou un organisme partenaire) de se charger de l’appariement des ensembles de données. Ce processus est décrit dans la section « Flux de données ».
Cependant, même des données qui ne concernent aucunement des individus peuvent être hautement confidentielles, comme la recette du Coca-Cola ou l’algorithme de recherche de Google
Bien qu’il existe de multiples façons de définir les données « identifiables » ou « désidentifiées », la définition proposée par la loi HIPAA, utilisée dans ce tableau, peut servir de référence pour déterminer si un ensemble de données peut être considéré comme désidentifié.
| Eléments de données autorisés par l’HIPAA | Désidentifié | Enssemble de données limité | Identifiable par la recherche |
|---|---|---|---|
| Noms ou initiales | X | ||
| Subdivisions géographiques infra-étatiques | X | ||
| Adresse postale | X | ||
| Pays, comté ou circonscription | X | X | |
| Code postal (5 chiffres ou +) | X |
X |
|
| Codes géographiques équivalents | X | X | |
| Code postal (3 chiffres)* * À condition que l’unité géographique correspondant à la combinaison de tous les codes postaux commençant par les 3 mêmes chiffres couvre plus de 20 000 personnes. |
X* | X | X |
| Dates directement associées à l’individu | X | X | |
| Année* | X* | X | X |
| Tout élément ou date indiquant que l’âge >89 ans *, par exemple, une année de naissance indiquant que l’âge >89 ans n’est pas autorisée dans un ensemble de données désidentifiées, même si les années y sont par ailleurs autorisées |
X | X | |
| Date de naissance | X | X | |
| Date d’admission ou de sortie | X | X | |
| Date de décès | X | X | |
| Coordonnées | X | ||
| Numéros de téléphone et/ou de fax | X | ||
| Adresses email | X | ||
| Numéros de compte et codes | X | ||
| Numéros de sécurité sociale | X | ||
| Numéros de dossier médical | X | ||
| Numéros de bénéficiaires d’assurance santé | X | ||
| Numéros de compte | X | ||
| Numéros de certificat/permis | X | ||
| Numéros d’identification et numéros de série des véhicules, plaques d’immatriculation | X | ||
| Codes d’identification et numéros de série des appareils | X | ||
| URL ou adresses IP | X | ||
| Données visuelles/biométriques | X | ||
| Caractéristiques biométriques | X | ||
| Empreintes digitales ou vocales | X | ||
| Portraits photographiques ou images similaires | X | ||
| Tout autre numéro, caractéristique ou code d’identification unique | X |
Tableaux récapitulatifs des exigences
| Données désidentifiées ou accessibles au public (HIPAA) | Ensembles de données limités (HIPAA/santé uniquement) | Données identifiables par la recherche (HIPAA) | |
|---|---|---|---|
| Accords d’utilisation des données* | La procédure est généralement simple, voire n’est pas nécessaire | Presque toujours requis. Un peu moins exigeant que les accords d’utilisation des données pour les données identifiées. | Presque toujours requis ; implique généralement un examen approfondi. |
| Supervision par l’IRB | Souvent exemptées par l’IRB. | Souvent exemptées par l’IRB. | Généralement soumis à un examen continu par l’IRB. |
| Consentement éclairé ou dispense de l’IRB | Pas requis par l’IRB si la recherche est exemptée. | ||
| Il est sans doute possible d’être dispensé de l’obligation d’autorisation individuelle, car le risque pour les sujets est faible. | Il est sans doute possible d’être dispensé de l’obligation de consentement éclairé par l'IRB. Cependant,vous devrez potentiellement fournir davantage de justifications que pour l’obtention d’une dispense pour des données désidentifiées. | Il peut être possible d’être dispensé de l’obligation de consentement éclairé par l’IRB. Cependant, il faudra probablement fournir des justifications solides et des preuves de la sécurité des protocoles de données mis en place pour obtenir une telle dispense. | |
| Autorisation individuelle de recherche (HIPAA) ou dispense de l’IRB | Pas requis par l’IRB si la recherche est exemptée. | ||
| Il est sans doute possible d’être dispensé de l’obligation d’autorisation individuelle, car le risque pour les sujets est faible. | Il est sans doute possible d’être dispensé de l’obligation d’autorisation individuelle. Cependant, vous devez potentiellement fournir davantage de justifications que pour obtenir une dispense pour des données désidentifiées. | Il peut être possible d’obtenir une dispense de l’obligation d’autorisation individuelle. Cependant, il faudra probablement fournir des justifications solides et des preuves de la sécurité des protocoles de données mis en place pour obtenir une telle dispense. |
|
| Sécurité des données* | Le fournisseur de données et l’IRB n’exigent généralement pas la mise en place de protocoles très stricts. | La mise en place de protocoles très stricts est généralement exigée soit par le fournisseur de données, soit par l’IRB. | La mise en place de protocoles très stricts est généralement exigée à la fois par le fournisseur de données et par l’IRB. |
*Ce tableau résume les exigences qui s’appliquent selon le degré d’identifiabilité des données administratives. Les chercheurs et les fournisseurs de données sont libres de prendre des précautions supplémentaires selon le degré de sensibilité des données, qui n’est pas forcément lié aux individus ni à la question de l’identifiabilité. Par exemple, les secrets commerciaux comme les recettes ne concernent pas des individus, et pourtant ils ne doivent jamais être divulgués, même dans le cadre du DUA et des protocoles de sécurité des données les plus stricts.
| Données désidentifiées ou accessibles au public (hors HIPAA) | Données identifiables par la recherche (hors HIPAA) | |
|---|---|---|
| Accords d’utilisation des données | La procédure est généralement simple ou n’est pas nécessaire. | Presque toujours requis ; implique généralement un examen approfondi. |
| Supervision par l’IRB | Souvent exemptées par l’IRB. | Généralement soumis à un examen continu par l’IRB. |
| Consentement éclairé ou dispense de l’IRB | Pas requis par l’IRB si la recherche est exemptée. | |
| Il est sans doute possible d’être dispensé de l’obligation de consentement éclairé par l’IRB, car le risque pour les sujets est faible. | Il peut être possible d’être dispensé de l’obligation de consentement éclairé par l’IRB, mais il faudra probablement fournir des justifications solides et des preuves de la sécurité des protocoles de données mis en place pour obtenir cette dispense. |
|
| Autorisation individuelle de recherche (HIPAA) | Ne s’applique pas aux données qui ne concernent pas la santé (c’est-à-dire qui ne relèvent pas de la loi HIPAA). | |
| Sécurité des données* | Le fournisseur de données et l’IRB n’exigent généralement pas la mise en place de protocoles très stricts. | La mise en place de protocoles très stricts est généralement exigée soit par le fournisseur de données, soit par l’IRB. |
*Ce tableau résume les exigences qui s’appliquent selon le niveau d’identifiabilité des données administratives. Les chercheurs et les fournisseurs de données sont libres de prendre des précautions supplémentaires selon le degré de sensibilité des données, qui n’est pas forcément lié aux individus ni à la question de l’identifiabilité. Par exemple, les secrets commerciaux comme les recettes ne concernent pas des individus, et pourtant ils ne doivent jamais être divulgués, même dans le cadre du DUA et des protocoles de sécurité des données les plus stricts.
EU General Data Protection Regulation (GDPR)
The General Data Protection Regulation (GDPR) introduces a major change in the way personal data of an EU resident is processed by an individual, a company or an organization located inside and outside the European Union. The regulation was approved by the EU Parliament in 2016, and came into effect in May 2018. The GDPR aims to regulate the use of personal data by imposing a specific way to ask for individual consent, specifying data subject rights and creating concrete sanctions.
Data processors and controllers must inform and ask consent from an individual about the data they collect and the possible use. The request for consent must be unambiguous and in an intelligible and easily accessible form, explicitly including the purpose for data processing.
The GDPR also introduces:
- The right to access, which allows citizens to question the data controller about their collected personal data (e.g., what kind of information about them has been collected, date and location of collection, purposes, etc.).
- The right to be forgotten, which grants citizens the right to have their data erased, meaning that individuals have more control over their personal data.
- Data portability, which aims to regulate migration of personal data of an individual from one control provider to another under his/her request.
GDPR Resources
- The official GDPR website and FAQs
- The Information Commissioner’s Office (ICO), the agency that will enforce the GDPR in the UK, has created a Guide to the GDPR.
Formuler une demande de données
Pour pouvoir extraire des données de leur base, les fournisseurs de données ont généralement besoin que leurs programmeurs rédigent une requête pour sortir les données spécifiques qui sont nécessaires à la recherche. Les chercheurs ne doivent pas partir du principe que les programmeurs connaissent le contexte spécifique de leur projet de recherche, et doivent donc rédiger une requête de données claire et concise comprenant les éléments suivants :
- La période visée par la demande, en mois/années civiles
- Le format de données accepté ou privilégié (par exemple ASCII, SAS, Stata)
- La structure des données (par exemple, plusieurs tableaux avec des clés uniques pour les fusionner ou un seul ensemble de données pré-fusionnées, format long ou format large)
- La liste des variables demandées
- Une explication ou des notes pour chaque variable
Précisez si vous avez ou non besoin de données identifiées ou d’autres éléments susceptibles d’être « sensibles ». Les fournisseurs de données partent souvent du principe que vous avez besoin d’accéder à des éléments d’identification explicites, comme le nom ou le numéro de sécurité sociale, et risquent de couper court à la conversation pour cette raison. Si vous n’avez pas besoin d’accéder à des données identifiées, indiquez-le explicitement : cela permettra sans doute d’accélérer le processus.
Évitez de demander « toutes les données ». Bien qu’il puisse être tentant de demander « toutes » les données ou d’en demander « autant que possible », cette approche présente des risques. Si les chercheurs ne spécifient pas les éléments de données dont ils ont besoin, ils risquent de recevoir moins de données que prévu ou de conclure un accord d’utilisation des données qui ne leur garantit pas l’accès à tous les éléments nécessaires. Une telle demande peut également susciter l’inquiétude de l’équipe juridique du fournisseur de données et créer des obstacles inutiles si les données sensibles ne sont pas réellement nécessaires à la recherche.
En outre, des jeux de données qui ne sont pas forcément sensibles ou identifiables en soi peuvent le devenir si on les combine à d’autres ensembles de données externes.
Demandez des variables d’intérêt spécifiques plutôt que des thématiques générales. Imaginons par exemple que les chercheurs souhaitent mesurer l’effet d’un programme de formation professionnelle sur la propension des individus à occuper un emploi « qualifié ». Plutôt que de demander des indicateurs généraux associés au fait d’occuper un emploi qualifié, les chercheurs doivent demander des variables spécifiques, comme les codes correspondants aux différents postes et leur intitulé. Sur la base d’une liste de variables spécifiques, le fournisseur de données sera peut-être en mesure de suggérer une variable d’intérêt supplémentaire en lien étroit avec ces variables, comme par exemple le code du secteur d’activité.
Assurez-vous que l’équipe de recherche et les fournisseurs de données interprètent bien les données et la requête de la même façon. Souvent, les chercheurs formulent leur demande de données en ayant à l’esprit un projet spécifique et un ensemble d’hypothèses. S’il n’a pas connaissance de ce contexte, le fournisseur de données peut interpréter une demande apparemment simple d’une manière complètement différente.
Par exemple, une requête en anglais portant sur « all checking transactions » peut être interprétée comme désignant l’ensemble des transactions effectuées par chèque ou l’ensemble des transactions effectuées à partir d’un compte chèque. Un appel téléphonique ou un échange d’e-mails détaillés peut favoriser l’identification et la résolution des problèmes éventuels.
Identifiez des interlocuteurs spécifiques au sein de l’organisation du fournisseur de données. De nombreuses demandes de données sont rendues inutilement compliquées à cause de la confusion engendrée par le fait que certains membres du personnel travaillent en dehors de leur domaine d’expertise habituel. La mise en place de relations fructueuses et le succès des demandes de données nécessitent souvent l’intervention de plusieurs personnes : un propriétaire de données, un directeur ou un représentant politique de haut niveau qui comprend le besoin général et l’importance de la demande de données et qui peut l’aider à franchir les différents obstacles bureaucratiques ; un expert en données ou en informatique qui connaît les éléments de données disponibles et peut se charger de l’extraction, de l’appariement et du transfert des données ; un expert programmatique ou institutionnel qui comprend le lien entre les données et les questions de recherche ; et un expert juridique qui maîtrise les exigences de conformité et la marche à suivre pour élaborer un accord d’utilisation des données.
Laissez le moins de place possible à l’interprétation. Demandez des données brutes plutôt que des variables de résultat calculées ou agrégées. Par exemple, au lieu de demander l’« âge », demandez la date de la prestation et la date de naissance, à partir desquelles l’âge pourra être calculé. Plutôt que de demander le « nombre de transactions supérieures à 100 dollars », demandez le montant en dollars de toutes les transactions.
Demande de données initiale :
- Données pour l’année qui précède et l’année qui suit l’intervention
- Distance entre le domicile et l’école
- Nombre d’enfants du ménage inscrits à l’école
- Date de naissance
- Âge
Commentaires du fournisseur de données :
« Comment voulez-vous que nous calculions la distance ? Nous avons un indicateur pour signaler si le trajet correspond à une ligne de bus scolaire, et de quelle ligne il s’agit. Avez-vous vraiment besoin à la fois de la date de naissance et de l’âge ? Nous partons du principe que vous ne voulez que les dossiers scolaires des écoles élémentaires. Quand a lieu l’intervention ? »
Demande de données actualisée, plus détaillée :
- Adresse de l’établissement scolaire
- Liste des effectifs scolaires de toutes les écoles du secteur, tous cycles compris, pour les années scolaires 2014-15 et 2015-16
- Numéro d’identification de l’élève
- Date de naissance
- Adresse du domicile de l’élève
- Ligne de bus (oui/non)
- Numéro de la ligne de bus
Flux de données
En tenant compte des contraintes éthiques, légales et financières, il convient d’élaborer, au cours de la phase de conception de l’évaluation aléatoire, un modèle de flux de données décrivant les liens qui seront établis entre les données administratives, les données d’enquête et les données de l’intervention. Ce modèle de flux de données doit inclure les éléments suivants :
- Les modalités de collecte des informations d’identification sur l’échantillon de l’étude
- Les éléments d’identification qui seront utilisés pour apparier les données de l’intervention et l’assignation du traitement, d’une part, et les données administratives, d’autre part
- L’entité ou l’équipe qui sera chargée de procéder à l’appariement
- L’algorithme qui sera utilisé pour l’appariement
- Le logiciel qui sera utilisé pour l’appariement
Dans le scénario le plus simple, le fournisseur de données accepte et est en mesure de transférer directement un ensemble de données entièrement identifiées aux chercheurs, en laissant toutes les autres étapes du processus d’appariement entre les mains de l’équipe de recherche. Cependant, bien souvent, des restrictions éthiques ou légales s’y opposent. Les sections qui suivent décrivent différents modèles de flux de données adaptés à des scénarios plus complexes.
Pour illustrer cette section (tableaux 5 à 7), nous utilisons un exemple théorique dans lequel l’assignation aléatoire est effectuée à partir d’une liste existante d’individus incluant les caractéristiques de référence, et où les données sur les résultats sont collectées à partir de deux sources externes
| Nom | Numéro de sécurité sociale | Date de naissance | Revenu | État |
|---|---|---|---|---|
| Jane Doe | 123-45-6789 | 01/05/1950 | $50,000 | Floride |
| John Smith | 987-65-4321 | 01/07/1975 | $43,000 | Floride |
| Bob Doe | 888-67-1234 | 01/01/1982 | $65,000 | Géorgie |
| Adam Jones | 333-22-1111 | 23/08/1987 | $43,000 | Floride |
| James Trudu | 123-45-9876 | 17/05/1960 | $50,000 | Floride |
| Joyce Gray | 587-157-8765 | 28/07/1980 | $43,000 | Floride |
| Philippe Zu | 224-85-6879 | 30/03/1980 | $65,000 | Géorgie |
| Alanna Fay | 341-78-3478 | 10/11/1979 | $50,000 | Floride |
| Nom | Numéro de sécurité sociale | Diabétique ? |
|---|---|---|
| Jane Doe | 123-45-6789 | O |
| John Smith | 987-65-4321 | N |
| Bob Doe | 888-67-1234 | N |
| Adam Jones | 333-22-1111 | O |
| James Trudu | 123-45-9876 | N |
| Joyce Gray | 687-157-8765 | O |
| Philippe Zu | 224-85-6879 | N |
| Alanna Fay | 341-78-3478 | O |
| Nom | Date de naissance | Possède une voiture ? |
|---|---|---|
| Jane Doe | 01/05/1950 | O |
| John Smith | 01/07/1975 | O |
| Bob Doe | 01/01/1982 | O |
| Adam Jones | 23/08/1987 | N |
| James Trudu | 17/05/1960 | O |
| Joyce Gray | 28/07/1957 | N |
| Philippe Zu | 30/03/1980 | N |
| Alanna Fay | 11/10/1979 | O |
Modalités de collecte des informations d’identification sur l’échantillon de l’étude
Les chercheurs et/ou leur partenaire de mise en œuvre ont parfois la possibilité d’avoir directement accès à un échantillon d’étude prédéfini, incluant les informations d’identification, par le biais de données administratives existantes. Il peut s’agir, par exemple, d’une liste des élèves d’une classe, des clients existants d’une banque, des médecins d’un hôpital ou des habitants d’une ville ayant fait l’objet d’un recensement complet et dûment identifié.
Dans d’autres cas, les chercheurs doivent procéder eux-mêmes à l’identification ou au recrutement d’un échantillon qui n’a pas été préalablement défini ou identifié. Il peut s’agir, par exemple, des nouveaux clients d’un magasin, des usagers d’une banque, des patients qui se rendent au cabinet d’un médecin ou des habitants d’une ville pour laquelle les chercheurs ne disposent pas de données de recensement. Dans ce cas, les informations d’identification devront probablement être obtenues de façon proactive par le biais d’une enquête initiale ou d’un formulaire d'admission.
Éléments d’identification utilisés pour faire le lien entre les ensembles de données
Les chercheurs doivent choisir quels éléments d’identification utiliser pour apparier les ensembles de données en se basant sur l’ensemble des éléments d’identification disponibles à la fois dans les données administratives et dans les données de mise en œuvre du programme. Compte tenu de cette contrainte, plusieurs conseils sont à prendre en compte pour faire ce choix :
N’utilisez que les éléments d’identification disponibles avant l’assignation aléatoire (par exemple, ceux qui ont été recueillis lors de l’admission ou de l’enquête initiale) pour faire le lien avec les dossiers administratifs des participants. En travaillant auprès des individus dans le cadre de l’intervention, il sera peut-être possible d’obtenir des éléments d’identification plus détaillés ou plus précis pour certains d’entre eux. Si ces informations sont plus facilement disponibles pour les membres du groupe de traitement que pour ceux du groupe témoin, l’utilisation d’informations actualisées risque d’introduire un biais, comme nous l’avons vu plus haut dans la sous-section « Couverture différentielle : l’observabilité dans les données administratives » de la section « Pourquoi utiliser des données administratives ».
Les participants à l’étude peuvent se montrer réticents à fournir des identifiants numériques sensibles (numéro de sécurité sociale, numéro d’étudiant, numéros de compte, etc.) au moment de l’admission, voire refuser de le faire. Même s’ils sont disposés à le faire, il se peut qu’ils ne connaissent pas ces informations par cœur. Bien que ce problème soit censé être équilibré entre les groupes expérimentaux dans la mesure où il se pose avant l’assignation aléatoire, l’absence de données d’identification adéquates peut réduire la taille effective de l’échantillon. Afin de maximiser le nombre d’éléments d’identification que vous pourrez recueillir au début de l’étude, veillez à nouer rapidement une relation de confiance avec les participants, à bien préciser quelles informations leur seront demandées et à leur expliquer comment leur vie privée et la confidentialité de leurs données seront protégées tout au long de l’étude.
Il est parfois possible de vérifier les éléments d’identification des individus, comme le numéro de sécurité sociale ou le numéro de compte, à partir de données administratives, à condition d’avoir recueilli le consentement des participants avant la randomisation et que les dossiers eux-mêmes soient antérieurs à l’assignation aléatoire.
Utilisez des éléments d’identification numériques dans la mesure du possible. Ils sont moins sujets aux fautes de frappe, aux fautes d’orthographe ou aux variantes que les chaînes de caractères (c’est-à-dire les éléments d’identification composés de mots ou de texte, comme le nom ou l’adresse), ce qui les rend plus faciles à apparier.
Utilisez des éléments d’identification qui ne risquent pas de changer régulièrement. La date de naissance et le numéro de sécurité sociale ne changent pas au fil du temps. En revanche, les noms sont susceptibles de changer, en particulier chez les femmes à la suite d’un mariage. De même, les identifiants uniques utilisés dans le cadre du programme ou de l’intervention sont parfois amenés à changer. Par exemple, imaginons que les participants se voient attribuer un porte-clés étiquette avec un code unique qui leur permet d’accéder aux services de la bibliothèque. Si un participant perd son porte-clés, il peut se voir attribuer un nouveau code et un nouveau porte-clés pendant la période d’intervention et d’évaluation. Pour éviter ce problème, il est important de disposer de plusieurs dossiers connexes et de méthodes d’identification de secours.
Entité chargée de procéder à l’appariement
Certaines agences ont l’habitude de répondre à des demandes d’extraction de données et d’appariement avec une liste spécifique de participants, et seront donc disposées à effectuer ce travail d’appariement au terme d’une discussion ou d’un accord relativement simple avec les chercheurs. En revanche, d’autres agences peuvent être plus réticentes à apparier des données en raison de craintes liées à la confidentialité ou à la légalité. Elles peuvent également être soumises à des contraintes de ressources qui limitent leurs capacités techniques ou la disponibilité de leur personnel. Dans ce type de situations, les chercheurs peuvent envisager de proposer des solutions créatives pour apporter un soutien pratique au processus d’appariement des données tout en préservant la confidentialité.
Les agences de données préféreront peut-être faire appel à leur propre personnel pour apparier les dossiers administratifs et les listes de participants à l’étude, mais elles peuvent aussi autoriser les chercheurs à procéder eux-mêmes à l’appariement, soit dans leurs locaux, soit sur un appareil sécurisé fourni et contrôlé par le fournisseur de données.
Pour choisir l’entité qui va effectuer l’appariement des données ainsi que le modèle de flux de données, il convient de tenir compte des réglementations en vigueur, des questions de confidentialité, des capacités en matière de sécurité des données et de la nécessité potentielle de pouvoir ré-identifier les données afin d’y ajouter des données de suivi ou de nouvelles sources de données.
Modèles de flux de données
Flux de données Option 1
Pour un échantillon donné d’individus spécifiques, les chercheurs peuvent envoyer au fournisseur de données un fichier d’identification, ou « finder file », contenant les identifiants uniques des participants à l’étude (tels qu’attribués par le chercheur) ainsi que des éléments d’identification personnelle. Le fournisseur de données utilise alors les éléments d’identification personnelle figurant dans le fichier d’identification pour sélectionner les dossiers administratifs correspondants. Il en supprime ensuite toutes les données d’identification personnelle et renvoie aux chercheurs les données appariées, y compris les identifiants de l’étude. Lorsque le partage des données se fait de cette manière, le fournisseur de données demande souvent au chercheur de stocker séparément le fichier d’identification et le fichier d’analyse désidentifié, et de s’engager à ne jamais les apparier.

Pour reprendre notre exemple, le chercheur envoie alors le fichier d’identification ci-dessous au fournisseur de données A et au fournisseur de données B. Étant donné que le fournisseur de données A ne dispose que des numéros de sécurité sociale et que le fournisseur de données B ne dispose que des dates de naissance, le chercheur va adapter le fichier d’identification pour chaque fournisseur de données. Dans ce scénario, c’est le chercheur qui crée l’identifiant de l’étude.
| Name | SSN | Date de naissance | Identifiant de l’étude |
|---|---|---|---|
| Jane Doe | 123-45-6789 | 01/05/1950 | 1 |
| John Smith | 987-65-4321 | 01/07/1975 | 2 |
| Bob Doe | 888-67-1234 | 01/01/1982 | 3 |
| Adam Jones | 333-22-1111 | 29/08/1987 | 4 |
| James Trudu | 123-45-9876 | 17/05/1960 | 5 |
| Joyce Gray | 587-157-8765 | 28/07/1957 | 6 |
| Philippe Zu | 224-85-6879 | 30/03/1980 | 7 |
| Alanna Fay | 341-78-3478 | 10/11/1979 | 8 |
Les fournisseurs de données A et B lui renvoient alors les fichiers suivants :
| Identifiant de l’étude | Diabétique ? | Identifiant de l’étude | Possède une voiture ? |
|---|---|---|---|
| 1 | O | 1 | O |
| 2 | N | 2 | O |
| 3 | N | 3 | O |
| 4 | O | 4 | N |
| 5 | N | 5 | O |
| 6 | O | 6 | N |
| 7 | N | 7 | N |
| 8 | O | 8 | O |
Le chercheur crée alors les fichiers suivants :
| Assignation du traitement | Identifiant de l’étude | Revenu | État | Diabétique ? | Possède une voiture ? |
|---|---|---|---|---|---|
| Traitement | 1 | $50,000 | Floride | O | O |
| Témoin | 2 | $43,000 | Floride | N | O |
| Traitement | 3 | $65,000 | Géorgie | N | O |
| Témoin | 4 | $43,000 | Floride | O | N |
| Traitement | 5 | $50,000 | Floride | N | O |
| Témoin | 6 | $43,000 | Floride | O | N |
| Traitement | 7 | $65,000 | Géorgie | N | N |
| Témoin | 8 | $50,000 | Floride | O | O |
| Nom | Numéro de sécurité sociale | Date de Naissance | Treatment Assignment | Study ID |
|---|---|---|---|---|
| Jane Doe | 123-45-6789 | 01/05/1950 | Traitement | 1 |
| John Smith | 987-65-4321 | 07/01/1975 | Témoin | 2 |
| Bob Doe | 888-67-1234 | 01/01/1982 | Traitement | 3 |
| Adam Jones | 333-22-1111 | 23/08/1987 | Témoin | 4 |
| James Trudu | 123-45-9876 | 17/05/1960 | Traitement | 5 |
| Joyce Gray | 587-157-8765 | 28/07/1957 | Témoin | 6 |
| Philippe Zu | 224-85-6879 | 30/03/1980 | Traitement | 7 |
| Alanna Fay | 341-78-3478 | 10/11/1979 | Témoin | 8 |
Avec cette méthode, le chercheur garde entièrement la main sur le tableau de correspondance entre les informations d’identification, les identifiants de l’étude et l’indicateur d’assignation aléatoire. Cela lui permet de s’assurer d’avoir la capacité technique de chercher des sources de données supplémentaires à l’avenir, sans être tributaire d’une collaboration à long terme avec des partenaires externes.
Toutefois, si les données administratives sont très sensibles, le fournisseur de données peut être réticent à l’idée que le chercheur ait accès à la fois au fichier d’identification et au fichier d’analyse désidentifié, car l’identifiant de l’étude pourrait être utilisé pour ré-identifier le fichier d’analyse. Les options deux et trois présentent dans le détail des modèles de flux de données qui répondent à cette inquiétude.
Flux de données option 2
Un partenaire de recherche privilégié (par exemple, un partenaire de mise en œuvre ou un tiers de confiance) peut être chargé de gérer la liste des participants et d’envoyer le fichier d’identification au fournisseur de données, sans jamais communiquer l’identité des individus aux chercheurs. C’est alors le fournisseur de données qui procède à l’appariement, avant d’envoyer le fichier d’analyse désidentifié directement au chercheur. Dans ce scénario, le partenaire de recherche n’a jamais accès aux données administratives et le chercheur n’a jamais accès aux éléments d’identification personnelle.
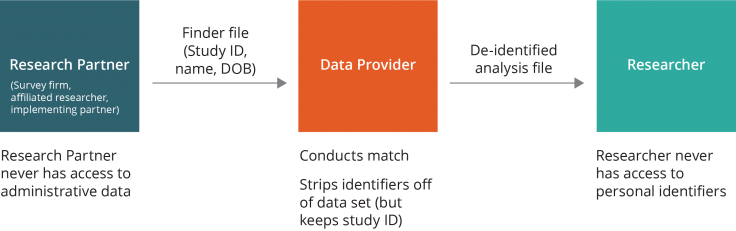
Si le partenaire de recherche est disposé à remplir cette fonction et en mesure de le faire, cette deuxième option offre une bonne solution de repli pour maintenir une séparation entre les données identifiées et les variables de résultat. Les chercheurs qui envisagent cette option doivent tenir compte de la solidité de la relation qui les unit au partenaire en question et définir des attentes réalistes pour la suite de la collaboration. Comme c’est le partenaire, et non le chercheur, qui gère la liste identifiée de l’échantillon d’étude, la coopération de ce partenaire sera indispensable pour toute étude de suivi ou évaluation à long terme. Pour garantir le maintien de la correspondance entre les éléments d’identification et l’identifiant de l’étude, les chercheurs peuvent envisager de prendre en charge le coût des infrastructures informatiques et des installations de stockage des données.
Le responsable de la mise en œuvre (ou l’entité tierce) envoie le fichier d’identification ci-dessous au fournisseur de données A et au fournisseur de données B. Étant donné que le fournisseur de données A ne dispose que des numéros de sécurité sociale et que le fournisseur de données B ne dispose que des dates de naissance, le partenaire peut adapter le fichier d’identification pour chaque agence. Dans cet exemple, c’est le responsable de la mise en œuvre qui crée l’identifiant de l’étude.
| Nom | Numéro de sécurité sociale | Date de naissance | Identifiant de l'étude |
|---|---|---|---|
| Jane Doe | 123-45-6789 | 01/05/1950 | 1 |
| John Smith | 987-65-4321 | 01/07/1975 | 2 |
| Bob Doe | 888-67-1234 | 01/01/1982 | 3 |
| Adam Jones | 333-22-1111 | 23/08/1987 | 4 |
| James Trudu | 123-45-9876 | 17/05/1960 | 5 |
| Joyce Gray | 587-157-8765 | 28/07/1957 | 6 |
| Philippe Zu | 224-85-6879 | 30/03/1980 | 7 |
| Alanna Fay | 341-78-3478 | 10/11/1979 | 8 |
Les fournisseurs de données A et B transmettent alors les fichiers suivants au chercheur (et pas nécessairement au partenaire). Le partenaire ou le responsable de la mise en œuvre enverra au chercheur un fichier similaire incluant l’identifiant de l’étude, l’assignation du traitement, les revenus et l’État.
| Identifiant de l'étude | Diabétique ? | Identifiant de l'étude | Possède une voiture ? |
|---|---|---|---|
| 1 | O | 1 | O |
| 2 | N | 2 | O |
| 3 | N | 3 | O |
| 4 | O | 4 | N |
| 5 | N | 5 | O |
| 6 | O | 6 | N |
| 7 | N | 7 | N |
| 8 | O | 8 | O |
Le chercheur crée alors un ensemble de données d’analyse comme dans l’exemple précédent. Le responsable de la mise en œuvre ou le partenaire se chargera de la création et de la mise à jour du tableau de correspondance.
Flux de données option 3
Si les données sont très sensibles, les fournisseurs peuvent refuser de communiquer toute information qui pourrait théoriquement être mise en lien avec des caractéristiques supplémentaires ou des personnes spécifiques. Par exemple, dans certaines juridictions, les statistiques de l’état civil et les données sur la natalité font l’objet de ce type de protection. Ces données doivent donc être analysées isolément ou en ne prenant en compte qu’un nombre limité de caractéristiques supplémentaires approuvées par le fournisseur de données.
La liste identifiée peut provenir du chercheur, du responsable de la mise en œuvre ou d’un partenaire. Les données de référence peuvent être incluses dans le fichier d’identification. Le fournisseur de données se chargera d’apparier le fichier d’identification avec ses propres données et de désidentifier le fichier conformément à ses propres standards. Cela peut inclure la suppression, la censure ou la catégorisation de certaines variables de référence. Par exemple, les âges peuvent être convertis en fourchettes et les indicateurs d’événements à faible probabilité, comme les arrestations ou les maladies rares, peuvent être supprimés.
Avec cette méthode, le fournisseur de données garde entièrement la main sur le tableau de correspondance entre le fichier d’identification et les variables de résultat ou les données administratives. Le fournisseur de données peut (ou non) maintenir ce tableau de correspondance en interne. Si c’est le cas, il sera en mesure de fournir des données administratives actualisées par la suite, qui pourront être appariées avec les données du précédent transfert.
Le responsable de la mise en œuvre (ou l’entité tierce) envoie le fichier d’identification ci-dessous au fournisseur de données A et au fournisseur de données B. Étant donné que le fournisseur de données A ne dispose que des numéros de sécurité sociale et que le fournisseur de données B ne dispose que des dates de naissance, le partenaire peut adapter le fichier d’identification pour chaque agence. Dans cet exemple, c’est le responsable de la mise en œuvre qui crée l’identifiant de l’étude.
| Nom | Numéro de sécurité sociale | Date de naissance | Revenu | État | Assignation du traitement |
|---|---|---|---|---|---|
| Jane Doe | 123-45-6789 | 01/05/1950 | $50,000 | Floride | Traitement |
| John Smith | 987-65-4321 | 01/07/1975 | $43,000 | Floride | Témoin |
| Bob Doe | 888-67-1234 | 01/01/1982 | $65,000 | Géorgie | Traitement |
| Adam Jones | 333-22-1111 | 23/08/1987 | $43,000 | Floride | Témoin |
| James Trudu | 123-45-9876 | 30/03/1980 | $50,000 | Floride | Traitement |
| Joyce Gray | 587-157-8765 | 28/07/1957 | $43,000 | Floride | Témoin |
| Philippe Zu | 224-85-6879 | 30/03/1980 | $65,000 | Géorgie | Traitement |
| Alanna Fay | 341-78-3478 | 10/11/1979 | $50,000 | Floride | Témoin |
Dans cet exemple, il ne serait pas possible de combiner les données des fournisseurs de données A et B. Le fournisseur de données A transmet le fichier suivant au chercheur. Il peut également décider de censurer les informations sur les revenus ou les données géographiques, s’il estime qu’elles sont trop spécifiques et potentiellement identifiantes.
| Assignation du traitement | Revenu | État | Diabétique ? | Possède une voiture ? |
|---|---|---|---|---|
| Treatment | $40,000-$60,000 | Floride | O | O |
| Control | $40,000-$60,000 | Floride | N | O |
| Treatment | >$60,000 | Géorgie | N | O |
| Control | $40,000-$60,000 | Floride | O | N |
| Treatment | $40,000-$60,000 | Floride | N | O |
| Control | $40,000-$60,000 | Floride | O | N |
| Treatment | >$60,000 | Géorgie | N | N |
| Control | $40,000-$60,000 | Floride | O | O |
Le fournisseur de données maintiendra peut-être le tableau de correspondance.
Flux de données option 4
Certaines agences n’ont ni les capacités nécessaires pour procéder à l’extraction et à l’appariement des données pour les chercheurs, ni la possibilité de partager librement un ensemble de données entièrement identifiées. Dans ce cas, un chercheur peut éventuellement venir effectuer l’appariement, ou y contribuer, sur place, dans les locaux du fournisseur de données, sous la supervision du personnel de ce dernier, et repartir avec un ensemble de données désidentifiées.
Cela peut se faire de manière informelle, ou bien le chercheur peut signer des formulaires pour intervenir en capacité d’employé bénévole du fournisseur de données le temps d’une journée ou plus. L’équipe de recherche peut également financer un assistant en poste chez le fournisseur de données. Dans ce cas de figure, il est possible que le fournisseur décide de restreindre l’accès du chercheur à Internet ou aux périphériques de stockage afin d’empêcher la divulgation de données confidentielles au cours de l’appariement. Cette approche réduit la charge de travail du fournisseur de données tout en maintenant un haut niveau de confidentialité.
Dans ce cas, le chercheur peut être autorisé ou non à conserver un tableau de correspondance entre les éléments d’identification et les identifiants de l’étude. Après avoir analysé l’ensemble de données désidentifiées ainsi obtenu, le fournisseur de données peut demander à ce que des mesures supplémentaires soient prises, comme dans le cas de l’option 3.
Cette approche permet au chercheur de garder davantage de prise sur l’algorithme d’appariement. Toutefois, si elle permet de libérer le fournisseur de données de la charge que représente l’appariement des données, les chercheurs doivent en revanche financer leurs propres déplacements, et la fenêtre dont ils disposent pour réaliser l’appariement et résoudre les problèmes éventuels est parfois très limitée.
Algorithmes d’appariement des données
En général, on distingue deux types de stratégies d’appariement : l’appariement « exact » (ou déterministe) et l’appariement « flou » (ou probabiliste). Que ce soit le chercheur, le fournisseur de données ou un tiers qui effectue l’appariement, il est essentiel de bien comprendre et de bien documenter la stratégie utilisée. Recourir à une stratégie d’appariement exact permet de minimiser le nombre de faux positifs (une « correspondance » est trouvée, mais il ne s’agit en fait pas de la même personne), mais peut également maximiser le nombre de faux négatifs (on ne trouve aucune « correspondance » alors qu’une même personne est présente dans les deux fichiers).
- Appariement exact. Une stratégie d’appariement « exact » consiste à faire le lien entre les éléments d’identification spécifiques contenus dans le fichier d’identification et les éléments d’identification présents dans les ensembles de données administratives. En cas de divergences, même mineures (par exemple, si le mois et le jour de la date de naissance sont inversés, ou s’il y a des fautes de frappe dans le nom de famille), les enregistrements ne seront pas identifiés comme correspondants, même s’ils le sont peut-être.
- Appariement probabiliste, ou correspondance floue. Les stratégies d’appariement probabiliste utilisent un algorithme plus sophistiqué pour tenir compte du fait que les éléments d’identification que contient le fichier d’identification peuvent ne pas correspondre exactement à ceux de l’ensemble de données administratives, mais peuvent être suffisamment proches pour être considérés comme une correspondance valable. Pour des raisons de reproductibilité et de transparence, l’algorithme ou le protocole permettant d’identifier une correspondance floue doit être clairement énoncé et appliqué. La comparaison manuelle des ensembles de données et la prise de décisions au jugé ne sont pas des méthodes reproductibles.
Par exemple, lorsqu’on souhaite apparier deux ensembles de données, les enregistrements identifiés comme des « correspondances » dépendent fortement des variables utilisées pour l’appariement, ainsi que du type et du degré de variance autorisés dans le cadre d’une correspondance floue.
| Enregistrement | Nom | Numéro de sécurité sociale | Date de naissance |
|---|---|---|---|
| A | Jane Doe | 123-45-6789 | 01/05/1950 |
| B | Jonathan Smith | 987-65-4321 | 01/07/1975 |
| C | Bob Doe | 888-67-1234 | 01/01/1982 |
| D | Adam Jones | 333-22-1111 | 23/08/1987 |
| E | Maria Anna Lopez | 532-14-5578 | 15/10/1965 |
| F | Sarah Franklin | 333-22-1111 | 23/08/1987 |
| Enregistrement | Nom | Numéro de sécurité sociale | Date de naissance |
|---|---|---|---|
| 1 | Jane Doe | 123-45-6789 | 05/01/1950 |
| 2 | John Smith | 987-65-4321 | 01/07/1975 |
| 3 | Bob Doe | 888-67-1243 | 01/01/1982 |
| 4 | Adam Jones | 23/08/1987 | |
| 5 | M. Anna Lopez | 532-14-5578 | 15/10/1965 |
| 6 | Sarah Franklin | 333-22-1111 | 23/08/1987 |
| Appariement exact | ||||
|---|---|---|---|---|
| Enregistrement | Correspondance floue | Sur le numéro de sécurité sociale seul | Sur le nom, le numéro de sécurité sociale et la date de naissance | Sur le nom et la date de naissance |
| A+1 | Correspondance possible | Apparié | Non apparié | Non apparié |
| B+2 | Correspondance possible | Apparié | Non apparié | Non apparié |
| C+3 | Correspondance possible | Non apparié | Non apparié | Apparié |
| D+4 | Correspondance possible | Non apparié | Non apparié | Apparié |
| E+5 | Correspondance possible | Apparié | Non apparié | Non apparié |
| F+6 | Apparié | Apparié | Apparié | Apparié |
Selon la structure des données et le traitement des enregistrements non appariés, les erreurs d’appariement sont susceptibles de diminuer la précision des estimations d’impact. Dans certaines circonstances, l’équilibre (ou plutôt l’absence d’équilibre) entre le taux de faux positifs et de faux négatifs peut même biaiser les estimations. Prenons par exemple le cas de l’appariement d’un ensemble donné d’individus avec leurs rapports d’arrestation. Dans la mesure où les registres d’arrestation ne contiennent que les personnes qui ont déjà été arrêtées, il n’existe aucun fichier permettant de confirmer qu’un individu n’a jamais été arrêté, de sorte que le chercheur attribuera probablement la valeur « pas d’arrestation » à tous les enregistrements pour lesquels aucune correspondance positive n’a été trouvée avec les registres d’arrestation. Le recours à une stratégie d’appariement exact minimise le risque que des crimes soient faussement attribués à des personnes qui n’en ont pas commis. Cependant, la présence de faux négatifs peut amener des individus ayant commis des crimes à se voir attribuer un casier vierge. Bien que ce type d’erreur d’appariement puisse se produire de manière aléatoire dans le groupe de traitement et le groupe témoin, elles peuvent néanmoins biaiser les estimations d’impact et/ou en diminuer la précision (Tahamont et al. 2015; Dynarski et al. 2013).
Imaginons que des chercheurs disposent de la liste suivante de participants à un programme :
| Enregistrement | Nom | Numéro de sécurité sociale | Date de naissance |
|---|---|---|---|
| A | Jane Doe | 123-45-6789 | 01/05/1950 |
| B | Jonathan Smith | 987-65-4321 | 01/07/1975 |
| C | Emer Blue | 547-94-5917 | 15/08/00 |
| D | Amy Gonzalez | 431-54-9870 | 02/12/89 |
| E | Bob Doe | 888-67-1234 | 01/01/1982 |
| F | Adam Jones | 333-22-1111 | 23/08/1987 |
| G | Maria Anna Lopez | 532-14-5578 | 15/10/1965 |
| H | Sarah Franklin | 333-22-1111 | 23/08/1987 |
Ils reçoivent le registre des arrestations suivant de la part de l’agence de justice pénale de l’État :
| Enregistrement | Name | Numéro de sécurité sociale | Date de naissance | Arrestations |
|---|---|---|---|---|
| 1 | Jane Doe | 123-45-6789 | 05/01/1950 | 5 |
| 2 | John Smith | 987-65-4321 | 01/07/1975 | 3 |
| 4 | Amy Gonzalez | 431-54-9870 | 02/12/1989 | 2 |
| 6 | Adam Jones | 23/08/1987 | 9 | |
| 7 | M. Anna Lopez | 532-14-5578 | 15/10/1965 | 2 |
Selon la stratégie d’appariement utilisée, il est possible qu’un individu se voie attribuer un casier judiciaire vierge alors qu’il a en fait déjà été arrêté :
| Nom | Sur le nom seul | Sur le numéro de sécurité sociale seul | Sur le nom, le numéro de sécurité sociale et la date de naissance | Sur le nom et la date de naissance |
|---|---|---|---|---|
| Jane Doe | 5 | 5 | 0 | 0 |
| Jonathan Smith | 0 | 3 | 0 | 0 |
| Emer Blue | 0 | 0 | 0 | 0 |
| Amy Gonzalez | 2 | 2 | 2 | 2 |
| Bob Doe | 0 | 0 | 0 | 0 |
| Adam Jones | 9 | 0 | 0 | 9 |
| Maria Anna Lopez | 0 | 2 | 0 | 0 |
| Sarah Franklin | 0 | 0 | 0 | 0 |
Logiciels d’appariement
Pour effectuer un appariement de type probabiliste (ou « flou »), il existe plusieurs options. Le module « reclink » de Stata est une option que les chercheurs en sciences sociales sont susceptibles de connaître. Il existe également des logiciels spécialement conçus pour l’appariement, tels que Merge Toolbox et Link Plus. D’autres chercheurs utilisent Elastic Search et Open Refine (anciennement Google Refine).
Annexes
Consentement et autorisation
Le consentement et l’autorisation sont des sujets connexes, et tous deux font l’objet d’un examen par les Institutional Review Boards ou les comités de protection de la vie privée. Bien que l’autorisation individuelle puisse être demandée dans le cadre de la procédure de recueil du consentement éclairé, le consentement et l’autorisation ne peuvent se substituer l’un à l’autre.
Consentement éclairé
Le consentement éclairé est un processus par lequel les sujets d’une étude sont informés des procédures, des objectifs, des risques et des avantages de la recherche et consentent volontairement à y participer. La Common Rule (45 CFR 46.116) et la politique de l’établissement dictent certaines composantes du consentement éclairé. Le ministère américain de la santé et des services sociaux (US Department of Health & Human Services) met également à disposition une fiche de conseils à ce sujet.
Seules les personnes qui ont atteint l’âge légal de la majorité peuvent donner leur consentement. Bien que les parents puissent consentir pour leurs enfants, l’IRB peut décider que les chercheurs doivent également obtenir l’assentiment des enfants à participer à la recherche, en plus du consentement de leurs parents.
Les fournisseurs de données souhaitent parfois examiner le formulaire de consentement éclairé de l’étude afin de s’assurer qu’il décrit précisément aux participants potentiels la nature des données issues de leur organisation qui vont être partagées, l’identité des personnes qui vont y avoir accès, la date de leur transfert et la manière dont elles seront protégées. Suite à cet examen, le fournisseur peut demander des modifications du formulaire de consentement éclairé de l’étude, qui devront ensuite être approuvées par un IRB. Les chercheurs qui demandent des données administratives pour un échantillon d’étude ayant déjà fait l’objet d’une procédure de consentement peuvent être obligés de recueillir de nouveau le consentement de chaque participant avant qu’un fournisseur de données n’accepte de partager ses dossiers administratifs (Lee et al. 2015).
Pour plus d’informations, consultez notre ressource sur les procédures d’admission et de recueil du consentement, ainsi que les ressources qui figurent en bas de cette page.
Autorisation individuelle de recherche (HIPAA)
Une autorisation est une attestation signée par un individu pour permettre à une entité relevant de la loi HIPAA d’utiliser ou de diffuser ses données de santé protégées. L’autorisation doit décrire les informations demandées et en expliquer l’objectif. Elle doit être rédigée dans des termes clairs et facilement compréhensibles par l’individu. Cette démarche est similaire au concept de consentement éclairé et est souvent intégrée au document de recueil du consentement éclairé. Toutefois, l’autorisation est soumise à un ensemble de critères différents et peut faire l’objet d’un accord écrit distinct, obtenu en dehors de la procédure de consentement éclairé.
Pour plus d’informations, voir les ressources en bas de cette page.
Dernière mise à jour : Septembre 2021
Ces ressources sont le fruit d’un travail collaboratif. Si vous constatez un dysfonctionnement, ou si vous souhaitez suggérer l'ajout de nouveaux contenus, veuillez remplir ce formulaire.
Accords d’utilisation des données
Un accord d’utilisation des données (DUA) fixe les conditions selon lesquelles un fournisseur de données va partager des données avec l’établissement d’origine du chercheur en vue de leur utilisation par ce dernier. Cet accord, qui doit généralement être approuvé par le conseiller juridique de l’établissement d’origine du chercheur, contient un certain nombre de dispositions qui peuvent avoir un impact significatif sur les protocoles de recherche concernés. De nombreuses universités disposent d’un modèle type d’accord contenant des termes et conditions que l’université juge acceptables et qui tiennent compte des besoins des chercheurs. L’utilisation d'un modèle pré-approuvé peut simplifier la procédure d’examen du dossier au sein de l’établissement qui a créé le modèle. Une initiative américaine regroupant 10 agences fédérales et 154 établissements (dont le MIT et d’autres grandes universités) a élaboré un modèle de DUA. Bien que la plupart des établissements préfèrent utiliser leur propre contrat-type, de nombreux établissements membres ont accepté d’utiliser ce modèle comme solution de rechange.
Vous trouverez ci-dessous la description de quelques éléments qui figurent généralement dans un accord d’utilisation des données et dont les chercheurs doivent tenir particulièrement compte lorsqu’ils négocient avec un fournisseur de données :
- Périodes d’examen et liberté universitaire de publication. Les fournisseurs de données exigent parfois de passer en revue le manuscrit de l’étude avant sa publication, soit pour avoir un premier aperçu des résultats, soit pour repérer toute divulgation accidentelle d’informations confidentielles. Cette demande peut être acceptée à condition que le chercheur conserve la liberté finale de publier, à sa seule discrétion, après avoir étudié en toute bonne foi les commentaires des fournisseurs de données. Par ailleurs, les chercheurs peuvent également décider de fixer des limites raisonnables au temps alloué à l’examen du manuscrit avant sa publication. Il s’agit d’une disposition importante, car il peut arriver que le fournisseur de données tente de supprimer des résultats désavantageux.
- Limites à la publication de statistiques sommaires. Certains fournisseurs de données imposent parfois des limites strictes concernant le nombre d’individus à inclure dans une « cellule » ou dans les statistiques sommaires désagrégées. Les chercheurs doivent être au courant de ces limites et s’assurer qu’elles sont raisonnables.
- Responsabilité individuelle. Les accords d’utilisation des données (DUA) sont généralement conclus entre le fournisseur de données et l’établissement d’origine du chercheur et ne doivent pas exposer personnellement le chercheur au risque de poursuites judiciaires en cas de non-respect de l’accord. Les chercheurs doivent être attentifs à la présence de tout formulaire ou addendum nécessitant une signature individuelle et consulter leur conseiller juridique avant de signer.
- Destruction ou restitution des données. Les fournisseurs de données exigent généralement que les chercheurs leur renvoient ou détruisent les informations d’identification personnelle (ou toutes les informations) au bout d’un laps de temps donné. Les chercheurs doivent veiller à ce que le délai alloué soit suffisant pour couvrir l’ensemble du processus de recherche, de publication et d’examen par les revues universitaires, en se demandant notamment s’ils risquent d’avoir besoin des informations d’identification pour effectuer un appariement avec d’autres données obtenues par la suite, ou si les données risquent de devoir être passées en revue à une date ultérieure.
Vous trouverez ci-dessous une description des éléments qui figurent généralement dans un DUA, ainsi que des conseils pour leur négociation :
- Description des données Là où certains fournisseurs de données exigent une liste détaillée des éléments de données demandés, d’autres se contentent d’une description générale. Une description générale facilite l’ajout d’éléments supplémentaires par la suite sans avoir besoin d’établir un avenant formel, mais le chercheur n’est pas forcément assuré d’obtenir tous les éléments nécessaires.
- Période couverte par les données. De nombreux fournisseurs de données permettent aux chercheurs de demander plusieurs années de données de manière prospective ; d’autres exigent qu’un avenant soit établi chaque année pour demander de nouvelles données.
- Fréquence et calendrier des transferts de données. La première extraction et le premier transfert de données peuvent demander plus de temps et nécessiter davantage de discussions et d’ajustements que les extractions suivantes. Il peut être utile de prévoir un transfert de données « test ».
- Protection de la vie privée des sujets de recherche. Certains fournisseurs de données demandent aux chercheurs de s’engager à ne pas utiliser les informations figurant dans le jeu de données pour contacter les sujets, leurs proches ou pour obtenir des informations supplémentaires à leur sujet (en d’autres termes, pour mener une enquête de « retraçage »).
- Personnel. Certains fournisseurs de données exigent la liste de toutes les personnes qui vont avoir accès aux données, tandis que d’autres permettent aux chercheurs principaux d’identifier les « catégories » d’individus qui auront accès aux données (par exemple, des étudiants ou des employés). La possibilité d’identifier des catégories plutôt que des individus spécifiques contribue à alléger la charge administrative en évitant d’avoir à effectuer des modifications à chaque fois qu’un membre du personnel intègre ou quitte l’équipe du projet.
Outre les éléments décrits ci-dessus, les DUA peuvent imposer aux chercheurs de fournir un protocole expérimental, et contiennent généralement des dispositions relatives à la sécurité des données, à la confidentialité, à l’examen par un IRB ou un comité de protection de la vie privée, à la rediffusion des données et à la répartition des responsabilités entre le fournisseur de données et l’établissement d’origine du chercheur. Pour plus d’informations sur la description du plan de sécurité des données dans le contexte d’un DUA, voir l’exemple de texte décrivant un plan de sécurité des données dans notre ressource distincte consacrée à ce sujet, ainsi que les ressources qui figurent en bas de cette page.
Calendrier
Obtenir l’accès à des données administratives est un processus complexe qui doit être initié dès la phase de conception du projet de recherche. Le temps nécessaire à l’établissement d’un accord d’utilisation des données est très variable et dépend notamment de la capacité du fournisseur à traiter ce type de demande de données, de la sensibilité des données et de la complexité de la procédure d’examen qui doit être effectuée par les deux parties avant de pouvoir signer un accord légal. Dans une analyse de 2015 sur les démarches d’acquisition de données auprès de 42 agences de données, MDRC a constaté qu’il s’écoulait généralement entre 7 et 18 mois entre la première prise de contact avec un fournisseur de données et la conclusion d’un accord juridique.7
Une grande partie de ce temps est consacrée à la double procédure d’obtention d’un avis favorable de l’IRB et de l’autorisation légale concernant la demande de données. Les deux procédures peuvent impliquer de longs délais de traitement, et les modifications apportées par l’une des entités doivent être examinées et approuvées par l’autre. Les IRB demandent souvent aux chercheurs de fournir un DUA signé avant d’approuver le protocole expérimental, tandis que les fournisseurs de données exigent l’approbation de l’IRB avant de signer un DUA. Pour pouvoir avancer, les équipes de recherche peuvent demander une autorisation provisoire à l’une des parties, en prenant soin d’expliquer clairement la procédure et les contraintes à l’ensemble des parties concernées. Afin de faciliter ce processus, il est judicieux de communiquer de manière proactive et régulière avec l’IRB et les partenaires de données.
De nombreux ensembles de données administratives mettent à disposition les données de manière différée, afin de laisser le temps au fournisseur de les saisir et de les nettoyer. Au-delà de ce délai prévu, les chercheurs doivent aussi prévoir un délai supplémentaire pour permettre au fournisseur d’extraire et de transférer les données. Cette opération peut prendre plusieurs semaines voire plusieurs mois, en fonction des capacités et de la charge de travail du fournisseur. Les chercheurs doivent s’attendre à devoir revenir plusieurs fois sur les stratégies d’appariement et les définitions des données avec le fournisseur de données, en particulier lors du premier transfert.
La présence de spécifications précises dans l’accord d’utilisation des données ou le protocole d’accord peut contribuer à définir clairement les attentes du fournisseur de données et du chercheur en ce qui concerne la date et la fréquence des extractions.
Encourager la coopération du fournisseur de données
Des incitations supplémentaires peuvent encourager le fournisseur à coopérer et à traiter en priorité une demande de données administratives. Selon les facteurs de tension qui nuisent à la coopération, les incitations peuvent prendre la forme d’une lettre de soutien de la part d’un cadre supérieur de l’organisation du fournisseur de données, d’un dédommagement financier pour le temps de travail du personnel et les ressources informatiques, ou d’une aide en nature sous la forme d’un travail d’analyse de données répondant aux besoins du fournisseur. Pour résoudre les problèmes de confiance, certains chercheurs font appel à des co-chercheurs issus de l’organisation du fournisseur de données, ou à des consultants en qui le fournisseur a confiance ou qui ont déjà travaillé pour lui.
Si les fournisseurs de données ont parfois accès à une grande quantité de données, l’analyse n’est pas forcément leur objectif premier. Par exemple, les coopératives de crédit, les ministères de la santé et de l’éducation et les systèmes scolaires ont accès à des données extrêmement utiles pour les chercheurs. Cependant, ces structures se concentrent sur la prestation de services, et leurs équipes d’analyse des données sont souvent très réduites (voire inexistantes). Fournir régulièrement à ces organismes des analyses pertinentes et intéressantes de leurs propres données peut donc leur être très utile et les inciter à traiter en priorité les besoins du chercheur.
Une approche plus ambitieuse consiste à proposer un stagiaire ou un assistant de recherche qui travaillera directement pour le fournisseur. Le rôle de cet assistant de recherche peut être de participer à l’extraction des données pour l’évaluation aléatoire, mais aussi d’aider le fournisseur dans d’autres domaines. Lorsqu’on propose ce type de soutien, il est recommandé de définir et d’expliquer concrètement les avantages que le fournisseur pourrait retirer des services de l’assistant de recherche, ainsi que la faisabilité logistique de cette solution pour le fournisseur (par exemple, les chercheurs peuvent proposer de vérifier les antécédents de l’assistant, de superviser son intégration et sa rémunération, etc.)
Nous tenons à remercier Julia Brown, Manasi Deshpande, Jonathan Kolstad, Megan McGuire, Kate McNeill, Adam Sacarny, Marc Shotland, Kim Smith, Daniel Prinz, Elisabeth O’Toole et Annetta Zhou pour leurs commentaires et leurs conseils précieux. Nous remercions Mary Ann Bates, Stuart Buck, Amy Finkelstein, Daniel Goroff, Lawrence Katz et Josh McGee d’avoir su reconnaître la nécessité de ce document et de nous avoir fait part de leurs idées et de leurs suggestions tout au long de son élaboration. Ce document a été relu et corrigé par Alison Cappellieri et Betsy Naymon, et traduit de l’anglais par Marion Beaujard. Alicia Doyon et Laurie Messenger ont effectué la mise en forme du guide, des tableaux et des figures. Le présent travail a pu être réalisé grâce au soutien de la Fondation Alfred P. Sloan et de la Fondation Laura and John Arnold. Toute erreur est de notre fait.
Avertissement : Ce document est fourni à titre d’information uniquement. Toute information de nature juridique contenue dans ce document a pour seul objectif de donner un aperçu général de la question et non de fournir des conseils juridiques spécifiques. L’utilisation de ces informations n’instaure en aucun cas une relation avocat-client entre vous et le MIT. Les informations contenues dans ce document ne sauraient se substituer aux conseils juridiques compétents prodigués par un avocat professionnel agréé en fonction de votre situation.
Merci d’envoyer vos commentaires, questions ou réactions à l’adresse suivante : na_resources@povertyactionlab.org
Additional Resources
L’Administrative Data Research Partnership soutient la recherche sur les données administratives au Royaume-Uni.
Le rapport « Cheaper, Faster, Better: Are State Administrative Data the Answer? » dresse un tableau de l’utilisation des registres administratifs de l’état civil et des données de Medicaid dans le cadre du projet Mother and Infant Home Visiting Program Evaluation-Strong Start (MIHOPE-Strong Start). Il offre ainsi une excellente vue d’ensemble des différentes étapes de la procédure d’acquisition de données administratives.