Nettoyage et gestion des données
Summary
Bien que les opérations de contrôle de la qualité effectuées sur le terrain doivent permettre de détecter la plupart des erreurs commises lors de la collecte des données, il faudra malgré tout prendre un certain nombre de mesures pour préparer les données collectées en vue de l’analyse. Cette ressource présente les principales étapes nécessaires au traitement et au nettoyage des données. La première partie décrit les bonnes pratiques à adopter en matière d’organisation des fichiers et du code, dans le but d’aider les autres utilisateurs (et vous-même) à repérer facilement les versions les plus récentes des fichiers et à comprendre les manipulations effectuées sur les données. La seconde partie de la ressource détaille les démarches à suivre pour préparer les données en vue de l’analyse. Si cette ressource se concentre sur le nettoyage des données avec Stata, des principes similaires s’appliquent à R et aux autres outils d’analyse de données.
Organisation des fichiers
La mise en place d’une structure de dossiers claire et précise dès le début de l’étude favorise la gestion cohérente des données, des documents et autres fichiers. En règle générale, les chercheurs négocient avec les partenaires de l’étude la définition d’un flux de données, puis ils travaillent en concertation pour élaborer un plan de stockage et de gestion des données et autres fichiers. Les fichiers sont généralement organisés par type : do-files, données brutes, données nettoyées et instruments d’enquête. Lorsque vous planifiez la structure des fichiers, assurez-vous de respecter a minima les points suivants :
- Préservez les données originales désidentifiées. Pour en savoir plus, voir la ressource de J-PAL sur la désidentification des données.
- Conservez les données, les fichiers de code et les résultats séparément, en veillant à inclure une documentation suffisante pour que l’ordre et l’étendue des manipulations effectuées sur les données apparaissent clairement. Parmi les formes de manipulation des données, citons l’exclusion, l’ajout ou la modification de certaines données.
- Il est également utile de maintenir une séparation entre les différentes étapes de la manipulation ou de l’analyse des données. Par exemple, conservez un do-file distinct pour le code de nettoyage des données (qui produit un ensemble de données nettoyées à partir des données brutes), un do-file pour le code d’analyse exploratoire (qui est utilisé pour explorer, étudier et tester les données, effectuer des régressions et produire des statistiques sommaires), et un do-file pour le code d’analyse finale (qui produit les résultats des estimations rapportés dans des tableaux LaTeX, des graphiques correctement formatés et annotés, etc.).
- Créez un « master do-file », c’est-à-dire un do-file unique qui lance tous les do-files pertinents (voir plus bas). Vous devez pouvoir exécuter séparément le master do-file, le code de nettoyage, le code d’analyse et le code qui produit les figures. Vous aurez parfois besoin de relancer une analyse spécifique ou de ressortir une table en particulier. Or, si vous devez exécuter l’intégralité du code, cela vous prendra énormément de temps.
- Pratiquez le contrôle de versions, dont il est question plus loin, et qui implique notamment l’archivage des versions antérieures. Cela permet de conserver les travaux antérieurs pour pouvoir y revenir par la suite.
- Lorsque vous définissez la structure de vos dossiers, tenez compte du flux de données du projet (quelles sont les personnes qui doivent avoir accès à telles ou telles données, comment les données vont être stockées/sauvegardées et comment les ensembles de données vont interagir entre eux).
Voici un exemple de structure de dossiers bien organisée :
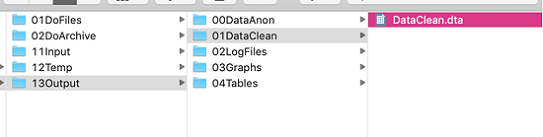
- Le dossier DoFiles contient les do-files classés par tâche :
- Le dossier DataPrep contient les do-files qui permettent d’importer les données dans Stata et de les désidentifier, ainsi que les do-files permettant de les nettoyer pour obtenir la version utilisée pour l’analyse.
- Le dossier DataAnalysis contient les do-files qui 1) exécutent les statistiques sommaires, 2) analysent les données sans produire de résultats formatés (ce qui prend du temps), et 3) produisent des tableaux LaTeX correctement mis en forme. Le fait de séparer ces différents types de fichiers vous permettra de relancer rapidement le code d’analyse, car le code qui permet de produire des tableaux mis en forme peut mettre un certain temps à s’exécuter.
- Le dossier DoArchive conserve les dossiers de do-files archivés et datés. Le fait d’archiver l’ensemble du dossier DoFiles au même endroit permet de préserver la structure sous-jacente des do-files qui ont fonctionné ensemble :
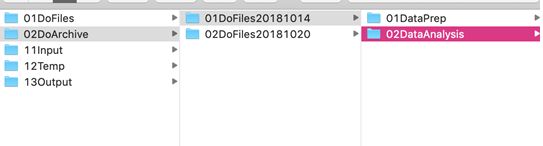
- Le dossier Input contient les données en cours d’importation et ne doit généralement subir aucune modification. Ce dossier contient deux sous-dossiers :
- DataRaw doit contenir le fichier chiffré contenant les données identifiées (ou les données contenant des informations susceptibles d’être utilisées pour identifier des individus), ou ne contenir aucune donnée. Pour plus d’informations sur le chiffrement des données, voir notre tutoriel sur Veracrypt, le tutoriel d’IPA sur Boxcryptor, ainsi que notre ressource sur les Procédures de sécurité des données pour les chercheurs. Personnel et membres affiliés de J-PAL : voir également la présentation sur la sécurité des données tirée de la formation pour le personnel de recherche de J-PAL.
- Le dossier DataCorrections doit contenir toutes les corrections effectuées sur la base de données identifiées, comme par exemple le remplacement d’un code GPS. Dans la mesure où ces corrections contiennent des éléments d’identification, elles doivent également être fusionnées à partir d’un fichier chiffré. Ne les écrivez pas dans un do-file. Voici la marche à suivre :
- Importer les données depuis DataRaw
- Importer toutes les corrections basées sur l’identifiant du sujet à partir de DataCorrections
- Supprimer les variables identifiantes et générer un numéro d’identification unique attribué de manière aléatoire en suivant la procédure décrite dans la ressource sur la publication des données.
- Le dossier Temp contient tous les fichiers temporaires et doit être nettoyé avant le début de l’analyse. Remarque : pour éviter tout encombrement superflu ou l’accumulation de fichiers inutiles (les nombreux fichiers qui ne sont utilisés qu’une seule fois, puis plus jamais), il est utile de créer des fichiers temporaires qui seront supprimés après l’exécution du programme. Avec Stata, la méthode la plus simple consiste à créer un fichier dans le dossier Temp puis, à la fin du do-file, à utiliser la commande erase(tempfile) pour supprimer ce fichier. On peut également utiliser une macro locale pour créer un fichier temporaire. Cette solution présente l’avantage de s’effacer automatiquement après l’exécution du code (pas besoin d’utiliser la commande erase). Cependant, elle peut s’avérer peu pratique si vous n’exécutez que des extraits de code très courts à chaque fois, dans la mesure où il s’agit d’une macro locale qui ne fonctionne donc que pour la séquence de code sélectionnée. La syntaxe à utiliser pour créer un fichier temporaire local est la suivante :
tempfile tempfilename
save `tempfilename'
/* this can then be used as any other dataset,
e.g.,can be merged, appended, etc. */
Il peut arriver que vous héritiez de dossiers mal organisés ou dont la structure n’est pas claire. Si vous ne décidez pas de la réorganiser entièrement, ce qui est très chronophage, vous pouvez créer un plan des dossiers, c’est-à-dire un document Excel ou Word (ou équivalent) qui répertorie tous les dossiers clés et leur contenu. Envisagez de créer un modèle de structure de dossiers à utiliser pour tous vos projets, ou pour toutes les vagues d’enquêtes d’un même projet. IPA propose aussi des modèles de structures de dossiers, et un modèle de structure de dossiers figure en annexe de cette ressource.
Organisation du code
Le code doit être organisé de manière à permettre au lecteur de comprendre ce qui a été fait : ce sera utile à la fois pour la poursuite de l’analyse et pour rédiger une description méthodologique dans le cadre d’un article. Les fichiers de code pouvant être très longs, une documentation complète du code permet à l’utilisateur de gagner du temps en limitant les tâches répétitives, les erreurs, les étapes oubliées et les tests inutiles. Plusieurs mesures peuvent être prises pour faciliter la compréhension du code.
En-tête et pied de page
Commencez par un en-tête bien structuré et informatif. L’en-tête de votre do-file doit contenir les éléments suivants :
- Le nom du projet, l’identité de la personne qui a rédigé le do-file, et à quelle date
- L’objectif du do-file
- La dernière date de modification du do-file
- La version du logiciel
Vous devez ensuite définir l’environnement de travail :
- clear all (la commande clear n’efface que les variables et les libellés. Elle n’efface pas les macros, les estimations stockées, les programmes, les scalaires, etc., tandis que clear all efface tout, comme son nom l’indique).
- Définissez la version de Stata pour la compatibilité ascendante. Par exemple, si vous définissez la version comme étant Stata 14, cela permettra aux utilisateurs de Stata 15 de reproduire exactement ce que vous avez fait. En revanche, si vous définissez la version comme étant Stata 15, les utilisateurs de Stata 14 ne pourront pas exécuter votre code. Sous Stata, cette opération s’effectue avec la commande version (numéro de version).
- Fixez la valeur de la graine pour que la randomisation soit reproductible. Cette opération doit se faire conjointement avec la définition de la version (point précédent) pour que la randomisation soit stable. Sous Stata, on utilise pour cela la commande set seed (graine). Pour plus d’informations sur le choix de la graine, voir le manuel d’aide de Stata.
- La commande set more off fait en sorte que le code s’exécute en continu, sans que Stata ne s’interrompe pour vous demander si vous souhaitez voir plus de résultats. set more off, permanently permet d’enregistrer cette préférence pour les programmes futurs (et set more on réactive l’option initiale).
- Forcez la fermeture du fichier log s’il y en a un d’ouvert.
- Un fichier log est un enregistrement complet de votre session Stata, y compris les résultats obtenus (à l’exception des graphiques) et les commandes intégrées à ces résultats. Au début de votre do-file (pas dans l’en-tête), démarrez le fichier log grâce à la commande log using.
- Attribuez un supplément de mémoire si nécessaire (via set mem (mémoire)).
* Author, date
* File loads raw data and carries out subroutine.do
* Written in Stata 14 on a Mac
clear all
/* clear memory
("clear" alone only clears variables and labels) */
version 14.2
/* later versions will do exactly what you did */
cap log close
/* closes any open log files; "capture"=no output,
even if the command fails (i.e., no open log)*/
set more off
/* running long code is not interrupted with
--- more ---. You set more off permanently
using set more off, perm */
set mem 100m
* assign additional memory if needed
set seed 20190802
/* doing anything random? set a seed so it's replicable! Make sure
you specify the Stata version or else your seed is not stable */
* Set working directory:
cd "/Users/Anon/Google Drive/Research/FileStructureExample"
/* Write one of those for each co-author and comment
out those you don't need. See the box below for alternative
methods You can use relative path names for everything in
the working directory. */
- Il est important de définir un répertoire de travail ou un chemin d’accès aux fichiers qui soit différent pour chaque co-auteur. À partir de ce stade, il convient d’utiliser des chemins d'accès relatifs. Un chemin d’accès absolu est composé de l’adresse complète du fichier (par exemple, C:/Users/username/Dropbox/folder1/folder2). En revanche, un chemin relatif indique à Stata que vous vous trouvez dans un répertoire de travail actuel (par exemple, C:/Users/username/Dropbox/folder1), de façon à ce que les chemins d’accès ultérieurs soient les mêmes pour tous les utilisateurs. L’utilisation d’un chemin d’accès relatif permet à chaque co-auteur de mettre en commentaire ou de modifier le chemin d’accès d’un autre co-auteur dans l’en-tête, sans avoir à modifier tous les chemins d’accès dans l’ensemble du do-file. Pour des raisons similaires, cette méthode est également utile si le chemin d’accès est amené à changer, par exemple lorsque vous archivez le dossier.
- Remarque : Si Windows, Linux et Mac reconnaissent bien les chemins d’accès qui utilisent « / », les ordinateurs Mac et Linux ne reconnaissent pas forcément « \ ». Il est donc préférable d’utiliser « / » dans les chemins d’accès, quel que soit votre logiciel d’exploitation.
Pour mettre en place un chemin relatif sous Stata, vous pouvez soit définir une macro globale, soit changer le répertoire de travail :
* Option 1: Using globals:
global user = "Name1"
*global user = "Name2"
// Comment out the names of other users
/* Note: globals are set permanently (until cleared). Locals
are only set for the duration of the current code sequence*/
if "$user" == "Name1" {
global path “C:/Users/user1/Dropbox/mainfolder/13Output”}
if "$user" == "Name2" {
global path “C:/Users/user2/Dropbox/mainfolder/13Output”}
* You can then use relative file paths, such as:
use "$path/13Output/01DataClean/Dataclean.dta", clear
* Option 2: Changing the working directory:
capture cd "C:/Users\user1/Dropbox/mainprojectfolder"
capture cd "C:/Users\user2/Dropbox/mainprojectfolder"
/* Note: if the command fails, using capture will ignore
the failure so that Stata continues on to the next line */
global data "data"
global output "output"
* You can then use relative file paths, such as:
use "13Output/01DataClean/DataClean.dta", clear
Remarque : L’option 1 présentée ci-dessus (utilisation de macros globales pour définir les chemins d’accès) peut s’avérer plus robuste face aux variations de style de programmation d’un auteur à l’autre.
À la fin de votre do-file, la commande capture log close permet de fermer et de sauvegarder votre fichier log. Là encore, l’utilisation de la commande capture permet à Stata de continuer à s’exécuter même s’il y a une erreur dans la commande (par exemple, s’il n’y a pas de log ouvert) et de supprimer le résultat de cette commande. exit arrête l’exécution du do-file, et exit, clear vous permet de fermer même si l’ensemble de données actuel n’a pas été sauvegardé.
Corps et commentaires
Pour éviter que les do-files ne deviennent trop lourds et trop complexes, il convient d’organiser le code en plusieurs sections distinctes, chacune étant pourvue de commentaires en en-tête (voir ci-dessous). Veillez également à indiquer clairement chaque tâche distincte, comme le fait de renommer des variables ou d’effectuer différentes régressions. Les commentaires doivent expliquer comment et pourquoi vous avez pris certaines décisions.
Concernant l’inclusion de commentaires en programmation, on distingue deux approches principales :
1. « Mieux vaut trop que pas assez » : Selon cette approche, mieux vaut faire plus de commentaires que nécessaire, en gardant à l’esprit que les décisions qui vous semblent évidentes aujourd’hui ne le seront pas forcément pour d’autres (voire pour vous-même dans le futur). Ceci étant dit, il est important de veiller à ce que les lignes de code et le commentaire correspondant soient cohérents : si vous mettez à jour une ou plusieurs lignes de code, pensez à mettre à jour le commentaire en conséquence.
2. Auto-documentation : Cette approche a pour objectif de limiter l’utilisation de commentaires. On dit que le code est « auto-documenté » lorsque les variables, les fonctions, les macros et les fichiers sont nommés de manière descriptive, claire et cohérente et que le code est structuré de façon à guider les lecteurs. En complément de ces pratiques et structures de dénomination descriptive, un logiciel de contrôle de versions ou des commentaires intégrés au code peuvent expliquer pourquoi certaines décisions ont été prises, par exemple pourquoi un certain type de valeur aberrante a été supprimé ou pourquoi le code utilise une commande plutôt qu’une autre (Pollock et al., 7). Certaines équipes peuvent décider de mettre en forme les commentaires de façon standardisée pour des raisons de cohérence et de clarté, là où d’autres opteront pour un système d’auto-documentation complète et n’utiliseront aucun commentaire. Maîtriser une méthode de rédaction de code auto-documenté demande du temps et des efforts, mais l’objectif d’un tel système est d’éviter toute erreur liée à la présence de commentaires obsolètes et de réduire les frais de maintenance liés au temps et au travail nécessaires pour maintenir les commentaires à jour (Gentzkow et Shapiro, 2014, 28).
Quelle que soit l’approche choisie, il est également utile de créer des marqueurs de commentaires pour signaler les événements importants ou certains types de décisions, comme la création ou l’exportation d’un tableau, d’un graphique ou d’un diagramme, la fusion et l’ajout d’ensembles de données, le changement de format d’une base de données (reshaping) et l’agrégation de données (collapsing), l’élimination des doublons et la modification d’un identifiant unique. L’utilisation systématique du même marqueur pour signaler le même type d’événement (par exemple la génération d’une nouvelle variable, l’établissement d’une limite supérieure pour une variable donnée, le remplacement de valeurs, etc.) facilitera ensuite la recherche de ce terme dans le do-file. Parmi les exemples de marqueurs de commentaires, on peut notamment citer /!\ et decision. Définissez les marqueurs utilisés dans la première section du do-file, après l’en-tête.
Sous Stata, il existe quatre façons principales d’interrompre le code pour ajouter des commentaires :
- * est utilisé pour les commentaires en pleine ligne. Utilisez-le pour créer des séparations de sections
- // est utilisé pour les commentaires de fin de ligne. Utilisez-le pour les marqueurs ou les commentaires courts
- /*...*/ est utilisé pour les commentaires en bloc. Utilisez-le pour les commentaires plus longs, en veillant toutefois à ce que la longueur de la ligne reste raisonnable (entre 80 et 100 caractères)
- /// est utilisé pour les sauts de ligne.
*****************************************************
*** Beautiful comments ***
*****************************************************
*If the line starts with * the whole line is a comment
// Short comments can be stored in an in-line comment:
sum var1, detail // in-line comment example
* You can break long commands over several lines with ///
/* Example: a graph with 3 lines for
control, HW, and FC groups: */
graph twoway ///
line nlnlScont _t if _t<=$ndays+5, sort lw(thick)||///
line nlnlShw _t if _t<=$ndays, sort lp(shortdash)||///
line nlnlSfc _t if _t<=$ndays, sort lp(longdash) ||///
leg(label(1 "Control") label(2 "Hw") label(3 "FC"))
/* Longer comments can go in a comment box,
enclosed by /* and */. /*
This is an example of a longer comment. */
/* Comment markers used in this do-file:
/!\ signifies an issue that needs further attention
// decision signifies a decision, such as every
time the data was manipulated during data cleaning */
** Comment markers in action:
isid uniqueid // /!\ id variable doesn't
// uniquely identify observations
duplicates report
duplicates drop // decision: dropped duplicates
Pseudo-code
Le pseudo-code est une ébauche de l’algorithme que vous prévoyez d’utiliser, rédigée dans un mélange d’anglais simple et de code. Il permet de réfléchir à la construction globale et aux avantages et inconvénients des différentes approches possibles avant de se pencher sur les détails spécifiques de la programmation. Si le programme est particulièrement long, il est beaucoup plus facile de modifier quelques lignes de pseudo-code que le code réel (ce qui peut nécessiter un important travail de correction d’erreurs). Il est donc intéressant de prendre le temps de travailler sur le pseudo-code en amont. Pour plus d’informations, voir le document Pseudocode 101, issu du cours du MIT intitulé Introduction to Computer Science and Programming Using Python.
Le pseudo-code peut également être utilisé à des fins de documentation : au lieu d’ajouter des commentaires au code après sa rédaction, ce qui peut entraîner des conflits si le code est mis à jour et ne concorde plus avec le commentaire, la démarche adoptée est préalablement documentée dans le pseudo-code. Notez que, lorsque vous utilisez des boucles (comme dans l’exemple ci-dessous), vous pouvez utiliser la commande set trace on pour déterminer quelles lignes de code fonctionnent.
*** Code in published .do file:
* Has all the information but is hard to fully understand.
local datetime_fields "submissiondate starttime endtime"
// format date time variables for Stata
if "`datetime_fields'" ~= "" {
foreach dtvar in `datetime_fields' {
tempvar tempdtvar
rename `dtvar' `tempdtvar'
gen double `dtvar'=.
cap replace`dtvar'=clock(`tempdtvar',"MDYhms",2025)
drop `tempdtvar'
}
}
On peut par exemple rédiger le pseudo-code suivant :
*** The same algorithm in pseudo code:
// Start with an auto-generated list of variables
// containing time and date information
// if list not empty:
{
// for each date-time variable in the list:
{
// save the original date-time variable "dtvar"
// under the temporary name "tempdtvar"
// create an empty variable "dtvar"
// decode the temporary variable
// and format it as a time-date field
// drop the temporary variable
}
}
Une fois que vous avez déterminé ce que vous voulez que l’algorithme accomplisse, vous pouvez compléter le pseudo-code par du vrai code :
*** Filling the pseudo code step by step with real code:
// Start with an auto-generated list of variables
// containing time and date information
local datetime_fields "submissiondate ///
starttime endtime"
// if list not empty:
if "`datetime_fields'" ~= "" {
// for each date-time variable in the list:
foreach dtvar in `datetime_fields' {
// save the original date-time variable "dtvar"
// under the temporary name "tempdtvar"
tempvar tempdtvar
rename `dtvar' `tempdtvar'
// create an empty variable "dtvar"
gen double `dtvar'=.
// decode the temporary variable
// and format it as a time-date field
cap replace`dtvar'=clock(`tempdtvar',"MDYhms",2025)
// drop the temporary variable
drop `tempdtvar'
}
}
Master do-file
Un « master do-file » est un fichier qui lance toutes les étapes de l’analyse dans l’ordre et les exécute en une seule fois. C’est un fichier utile lorsque vous avez besoin d’exécuter l’ensemble du programme, notamment si quelqu’un d’autre souhaite vérifier la reproductibilité de votre code ou les résultats avant de soumettre l’article. Exécuter le programme dans son intégralité peut toutefois être très chronophage, et il est donc utile de rédiger le code de manière à ce que les fichiers individuels puissent également s’exécuter de façon indépendante. Au sein du master do-file, lancez chaque programme en utilisant la commande do (nom du do-file).
Pour que le master do-file fonctionne, il faut que l’adresse des fichiers soit la même dans le master do-file et dans les fichiers individuels. Le master do-file doit également inclure toutes les commandes écrites par les utilisateurs qui sont utilisées dans le code (c’est-à-dire les commandes Stata rédigées par des utilisateurs, qui ne font pas partie des fonctions par défaut du logiciel), ainsi que le code qui les installe (ces commandes doivent également figurer dans le fichier readme). Vous trouverez ci-dessous un exemple de master do-file. Notez toutefois que la capture d’écran ne montre pas tous les éléments de l’en-tête, même si ceux-ci doivent être inclus dans le master do-file comme dans n’importe quel autre do-file.
* Set working directory:
cd "/Users/Anon/Google Drive/Research/FileStructureExample"
/* If you may need to use files that are not in the working
directory, you may want to specify the path name upfront: */
global datapath "/Users/Anon/Google Drive/Research/FileStructureExample/13Output/0DataAnon"
global dopath "/Users/Anon/Google Drive/Research/FileStructureExample/2DoArchive/1DoFiles20180114"
// clear out the temporary directory
cd "./11Temp"
local tempfilelist : dir . files "*.dta"
foreach f of local tempfilelist {
erase "`f'"
}
cd "../"
log using "./13Output/2Logfiles/ProjectNameLog.txt",replace
// Import data and clean it
do "${dopath}/1DataPrep/Clean.do"
// Run regressions
do "${dopath}/2DataAnalysis/2Analysis.do"
// Make LaTeX tables and graphs for the paper
do "${dopath}/2DataAnalysis/3LaTeXandGraphs.do"
/* Note! $datapath is used in the individual do-files! Make sure
your use of global macros vs. relative file paths is consistent
everywhere */
Documentation et contrôle de versions
La documentation et le contrôle de versions sont des composantes essentielles de tout projet. La documentation retrace le cheminement de votre réflexion, permettant ainsi à des personnes tierces (mais aussi à vous-même dans le futur) de comprendre pourquoi certaines décisions ont été prises. Elle présente le double avantage d’aider les personnes extérieures à comprendre vos résultats et d’améliorer la reproductibilité de votre travail et, par conséquent, l’intégrité de la recherche. Pendant la phase de nettoyage et d’analyse des données, l’approche la plus simple consiste à documenter les décisions de programmation purement mécaniques directement dans le code à l’aide de pseudo-code ou de commentaires clairs. Les décisions plus importantes, comme l’imputation des variables ou l’élimination des valeurs aberrantes, doivent par ailleurs être documentées dans un fichier séparé et évoquées plus tard dans l’article de recherche. Des outils de gestion des tâches, comme Asana, Wrike, Flow, Trello ou Slack, peuvent être utilisés pour documenter les tâches, les décisions et autres travaux effectués en dehors de la programmation. Ces informations pourront ensuite être consignées dans un fichier readme, dans l’article de recherche ou dans un autre type de document.
Le contrôle de versions permet de conserver les versions antérieures des fichiers, de sorte qu’aucune modification n’est irréversible (sans cela, lorsque vous enregistrez une modification et que vous fermez ensuite le fichier, il est difficile d’annuler la modification). C’est particulièrement important lorsqu’un fichier fait l’objet de plusieurs révisions, comme c’est le cas lors du nettoyage des données. Pour assurer le contrôle de versions, les deux options les plus répandues sont le contrôle manuel et l’utilisation de Git et de Github. Dropbox offre également des fonctionnalités limitées de contrôle de versions, mais ne stocke les versions antérieures des fichiers que pendant une durée limitée.
Pour le contrôle de versions manuel, comme indiqué plus haut, le fait d’archiver et de dater l’ensemble du dossier de do-files en même temps permet de préserver la structure qui a fonctionné ensemble. Conservez la version actuelle de chaque fichier dans votre répertoire de travail et datez chaque version en utilisant le format AAAA_MM_JJ ou AAAAMMJJ, ce qui vous permettra de trier les fichiers par date. N’ajoutez pas d’initiales à la fin des noms de fichiers, car cela peut rapidement prêter à confusion. En d’autres termes, utilisez des noms de fichiers du type cleaningcode_20190125, plutôt que cleaningcode1_SK.
Une autre solution consiste à utiliser Git et GitHub, ou SVN. Git nécessite une période d’apprentissage mais présente des avantages indéniables par rapport au contrôle de versions manuel. Par exemple, plusieurs utilisateurs peuvent travailler simultanément sur un même fichier et en synchroniser les modifications, qui sont par ailleurs documentées, ce qui facilite le repérage des changements effectués d’une version à l’autre. Git est donc particulièrement utile pour les projets dans le cadre desquels plusieurs personnes sont amenées à collaborer sur les mêmes fichiers. Parmi les ressources utiles pour se familiariser avec Git, citons la formation à Git/GitHub d’Udacity et la rubrique d’aide de GitHub. Personnel et membres affiliés de J-PAL : voir également la présentation à ce sujet issue de la formation pour le personnel de recherche de J-PAL.
Quelle que soit l’option choisie, les deux points essentiels qu’il faut toujours garder à l’esprit pour le nettoyage des données sont les suivants
- Documenter toutes les modifications apportées aux données brutes. Cette opération peut être réalisée facilement dans le do-file de nettoyage en utilisant des commentaires et le code utilisé pour effectuer les changements. Les modifications effectuées dans Excel ou autre programme similaire ne seront pas documentées, c’est pourquoi il est important de tout faire sous Stata, R ou autre programme du même type.
- Ne jamais écraser le fichier de données brutes. Pour éviter cela, sauvegardez les fichiers de données nettoyés dans un autre dossier, selon la procédure décrite ci-dessus.
Nettoyage des données
Introduction
Le nettoyage des données est un prélude important à toute analyse. Même si l’enquête est réalisée de manière consciencieuse, il peut arriver que des fautes de frappe ou d’autres erreurs soient commises au moment de la collecte des données, ou que la présence de valeurs aberrantes, si elles ne sont pas correctement prises en compte, fausse les résultats. Avant de procéder à une quelconque analyse, il est donc important de commencer par nettoyer les données, qu’il s'agisse de données originales recueillies sur le terrain ou de données administratives. Cette opération peut être chronophage, mais les efforts consentis au départ permettront d’économiser beaucoup de temps et d’énergie par la suite. Remarque : la première étape du traitement des données doit toujours consister à chiffrer les données qui contiennent des informations susceptibles d’être utilisées pour identifier les individus.
Tout au long du processus de nettoyage des données, les deux points les plus importants à garder à l’esprit sont les suivants :
- Documenter toutes les décisions
- Ne jamais écraser le fichier de données brutes.
En documentant toutes les tâches de nettoyage des données et en préservant le fichier de données d’origine, vous vous assurez que toute erreur peut être annulée et que les mesures qui ont été prises pour nettoyer les données peuvent être reproduites. Cette démarche est particulièrement importante pour la transparence de la recherche et les tests de robustesse. Par exemple, les chercheurs peuvent tester la stabilité des résultats en fonction de différents critères de nettoyage/troncage (comme la winsorisation ou l’élimination de toutes les observations au-dessus du 95e ou du 99e percentile de la distribution). Le nettoyage des données doit être effectué sur les données désidentifiées (dans la mesure où les données identifiées ne seront de toute façon pas utilisées dans l’analyse). Pour plus d’informations sur le chiffrement des données identifiées, voir ici. Pour plus d’informations sur la désidentification des données, voir ici.
Étapes
1. Configurer votre fichier
Suivez les étapes décrites plus haut : créez un en-tête qui efface le contenu de l’environnement, définit le répertoire de travail, la graine et la version, et contient toutes les informations requises, notamment le nom du projet, les co-auteurs, l’objectif du do-file, sa date de création, etc.
2. Importer et fusionner vos données
- Dans votre do-file, importez et fusionnez les fichiers selon vos besoins. Le fait de réaliser cette opération dans votre do-file permet de documenter l’importation : une tierce personne (ou vous-même dans le futur) pourra ainsi exécuter le do-file et savoir exactement quel fichier de données brutes a été importé.
- Sous Stata, utilisez la commande merge 1:1 lorsque chaque observation de la base de données principale correspond à une seule observation de la base de données appariée. Si ce n’est pas le cas, utilisez merge m:1 ou merge 1:m (et non merge m:m. Pour savoir pourquoi, voir la dernière diapositive de la présentation de l’atelier sur Stata de Kluender & Marx).
- Vérification : Les fichiers ont-ils été correctement fusionnés ? Vérifiez quelques observations spécifiques pour vous en assurer.
- Vérification : Quelles observations n’ont pas pu être appariées ? (Sous Stata : tab _merge)
3. Comprendre vos données
- Utilisez la fenêtre d’exploration pour consulter vos données.
- Examinez la distribution de chaque variable (tab; kdensity; sum var, detail). Y a-t-il des problèmes évidents ? Il peut notamment s’agir :
- De fautes de frappe (par exemple, une personne âgée de 500 ans), ou d’autres problèmes de saisie de données (par exemple au niveau des unités)
- De valeurs aberrantes, qu’elles soient ou non plausibles
- D’erreurs logiques telles que :
- Des répondantes très âgées ou très jeunes qui sont enceintes
- Des enfants plus âgés que leurs parents
- Des variables censées rester fixes dans le temps qui varient (par exemple, le district où vit le ménage)
- Vérifiez si les moyennes restent identiques dans le temps : tab year, sum(timeinvariant_var)
- Vérifiez également les entrées « autre » de vos variables catégorielles (voir plus bas)
- Recherchez la présence de doublons dans les identifiants uniques (sous Stata : isid id_variable vous indique si la variable id_variable identifie les observations de manière unique. Il existe également d’autres commandes utiles, comme duplicates report, duplicates list, etc.).
- Remarque : Idéalement, cette opération doit être effectuée pendant la collecte des données de façon à pouvoir consulter le personnel de terrain pour déterminer si les doublons sont dus à des identifiants mal attribués ou à des soumissions en double.
- Valeurs manquantes : Vérifiez le nombre d’observations pour chaque variable. Sous Stata, la commande tab variable, missing vous indique la proportion d’observations manquantes pour une variable donnée.
- Y a-t-il des signes évidents de censure ou de troncature ? (Par exemple si de très nombreux ménages comptent précisément 6 membres et qu’aucun n’en compte 7). Cela peut notamment se produire sur des variables comme le revenu, les biens et l’âge, ainsi que sur les variables pour lesquelles on demande au répondant d’énumérer tous les éléments d’une catégorie donnée et de répondre à des questions sur chacun d’entre eux (comme un inventaire ou un recensement des terrains agricoles d’un ménage, où le répondant doit ensuite répondre à des questions sur chacun de ces terrains).
- Vérifiez le type de chaque variable (vous pouvez pour cela utiliser la commande describe). Certaines variables numériques sont-elles codées comme des variables de type chaîne de caractères (texte) ? Voir ci-dessous pour plus d’informations sur la gestion des chaînes de caractères.
- Assurez-vous que les heures et les dates sont codées de manière uniforme.
- Vérifiez que vos données ont le bon format (large ou long) pour votre analyse. Dans un format large, un identifiant unique (comme l’identifiant du ménage) prend une valeur différente pour chaque observation (en d’autres termes, il l’identifie de manière unique). En revanche, dans un format long, une combinaison d’identifiants (comme l’identifiant du ménage et le numéro de la vague d’enquête) est nécessaire pour identifier de manière unique chaque observation. Sous Stata, la fonction reshape vous permet de faire passer vos données d’un format large à un format long ou d’un format long à un format large.
Décisions à prendre
Erreurs évidentes
- Effectuez des recoupements et utilisez toutes les informations dont vous disposez pour corriger les erreurs. Par exemple, dans le cas d’un homme déclaré enceinte, vous pouvez vérifier la relation de l’individu avec le chef du ménage, ainsi que la composition du reste du ménage, afin de déterminer si l’homme enceinte est en fait une femme enceinte ou un homme qui ne l’est pas.
- Si vous disposez d’une enquête initiale ou finale, ou de données de panel, utilisez les observations appariées d’autres vagues d’enquête pour recouper les données (par exemple, appariez les identifiants individuels d’autres vagues d’enquête pour déterminer le sexe de la personne).
- Si vous ne parvenez pas à trouver la bonne valeur (par exemple, à déterminer si l’homme enceinte est en fait une femme enceinte ou un homme non enceinte), remplacez la valeur incorrecte par une valeur manquante. Utilisez les valeurs manquantes « étendues » de Stata pour coder la raison pour laquelle la valeur est manquante (par exemple, .n=non applicable. Voir également les normes proposées par IPA pour les valeurs manquantes étendues).
Valeurs aberrantes
À moins qu’une observation ne constitue une erreur évidente (et que sa vraie valeur soit elle aussi évidente), n’essayez pas de deviner quelle devrait en être la valeur.
- Remarque : Les valeurs aberrantes peuvent être supprimées lors de l’analyse. On peut notamment supprimer toutes les observations situées au-dessus du 99e percentile ou en-dessous du 1er percentile, par exemple, ou effectuer une winsorisation, qui consiste à remplacer toutes les valeurs supérieures ou inférieures à un percentile donné, par exemple le 99e ou le 1er, par la valeur correspondant à ce percentile. En revanche, au moment du nettoyage des données, il est généralement préférable de ne pas supprimer les valeurs aberrantes (même si vous prévoyez de le faire lors de la phase d’analyse). En effet, il est possible que vos partenaires de recherche ou d’autres personnes souhaitent utiliser l’ensemble de données pour réaliser d’autres analyses et qu’ils traitent les valeurs aberrantes de façon différente. Expliquez comment traiter les valeurs aberrantes à tous les autres membres de l’équipe qui vont participer à l’analyse des données.
- Si vous excluez les valeurs aberrantes de l’analyse (plutôt que de les winsoriser), utilisez les valeurs manquantes étendues de Stata selon la procédure décrite ci-dessous pour préciser la raison pour laquelle la nouvelle valeur est manquante.
Valeurs manquantes
- Idéalement, les « vraies » valeurs manquantes, par exemple lorsque le sujet a interrompu l’enquête, doivent être détectées pendant la collecte des données pour que les enquêteurs puissent relancer le répondant et obtenir ces valeurs. Si les valeurs manquantes sont repérées à un moment où il n’est plus possible de collecter davantage de données, il convient, au minimum, de recoder les valeurs manquantes pour indiquer la raison de leur absence (si elle est connue).
- Si le code des valeurs manquantes était -999, -998, etc. dans l’enquête, vous pouvez remplacer ces codes par les valeurs manquantes étendues de Stata (.a, .b, .d, .r, etc.), afin d’éviter que les valeurs manquantes ne faussent la distribution si quelqu’un oublie d’en vérifier la présence.
- Le fait d’associer un code de valeur manquante distinct à chaque raison permet également de conserver les informations. Les codes standard sont les suivants : .d=don’t know (ne sait pas), .r=refusal (refus), .n=N/A. Vous pouvez également utiliser un autre code pour signaler les valeurs « éliminées pendant le nettoyage ». Nous vous recommandons de suivre les normes établies par IPA pour le traitement des valeurs manquantes. Conformément à ces lignes directrices, la valeur manquante standard sous Stata (.) doit être réservée aux vraies valeurs manquantes. Vous pouvez également indiquer les erreurs de programmation ou les erreurs commises par l’enquêteur, par exemple si la réponse de l’enquêté a été mal saisie par l’enquêteur (notamment pour les coordonnées GPS ou les codes de facturation, les numéros d’identification, etc.).
- Sous Stata, on peut recoder les valeurs d’un formulaire SurveyCTO en utilisant la commande mvdecode :
mvdecode variable, mv(-999=.d \-998=.r \-997=.d)
- Se contenter de recoder les données manquantes peut s’avérer suffisant si celles-ci sont aléatoires. Cependant, dans la mesure où ce n’est généralement pas le cas, une telle approche risque de biaiser vos résultats. Expliquez comment traiter les données manquantes à tous les autres membres de l’équipe qui vont participer à l’analyse des données. Vous trouverez une liste d’éléments à prendre en compte pour déterminer comment traiter le problème des données manquantes dans cet article du blog « Metrics Monday » de Marc Bellemare.
- Si vous décidez de prendre des mesures supplémentaires pour résoudre le problème des valeurs manquantes, plusieurs options s’offrent à vous :
- Imputer les valeurs manquantes : Si vous décidez d’imputer certaines valeurs, veillez à documenter clairement la méthode d’imputation utilisée dans le code. Parmi les méthodes d’imputation des valeurs manquantes, on peut notamment citer :
- L’agrégation constitue une alternative possible à l’imputation. Par exemple, si vous analysez des données sur le prix des terrains mais qu’il manque des données sur certains villages d’un district donné, vous pouvez remplacer les valeurs manquantes au niveau de ces villages par la moyenne ou la médiane du district.
- Une approche par variables instrumentales, si vous disposez d’un instrument plausible pour la variable manquante (ce qui est peu probable).
Traitement des variables de chaîne (string)
Lorsque vous programmez votre enquête, limitez autant que possible l’utilisation de chaînes de caractères (par exemple, utilisez des codes et des libellés de valeur pour les districts, plutôt qu’une variable de chaîne contenant le nom du district écrit en toutes lettres). Cela fera gagner du temps aux enquêteurs tout en réduisant le nombre d’erreurs commises lors de la saisie des données (par exemple, si le mot « homme » est remplacé par « homem »). La section consacrée aux « string functions » du manuel Stata contient un certain nombre de commandes utiles, et l’IFPRI propose également un guide utile qui traite de la manipulation des chaînes de caractères. Voici quelques commandes Stata qui sont particulièrement utiles pour nettoyer les variables de chaîne de caractères :
- Convertissez les variables textuelles en valeurs numériques en utilisant encode, qui attribuera automatiquement un libellé à la variable numérique (les valeurs seront toutefois attribuées dans l’ordre alphabétique, par exemple, 1=Allston, 2=Brighton, 3=Cambridge, 4=Somerville, que vos données soient ou non dans cet ordre). Avec encode, vous devez générer une nouvelle variable (par exemple, encode stringvar1, gen(numericvar1)).
- La commande destring convertit également les chaînes de caractères en variables numériques si la chaîne est entièrement composée de chiffres, mais elle n’attribue pas de libellé aux nouvelles valeurs. Avec destring, vous pouvez remplacer la variable de chaîne par une variable numérique (par exemple, destring var1, replace).
- Remplacez tous les caractères des valeurs de la variable de chaîne par des majuscules ou des minuscules à l’aide de replace(variable)=upper(variable) ou replace(variable)=lower(variable)
- Supprimez les espaces au début ou à la fin des valeurs de la variable de chaîne (par exemple, remplacez « Homme » par « Homme ») à l’aide de trim(stringvar). La syntaxe est la suivante : replace stringvar=strtrim(stringvar).
- Créez des variables indicatrices pour différentes valeurs de la variable de chaîne avec la commande tab var1, gen(newvar). Cette commande crée une nouvelle variable indicatrice pour chaque valeur de var1. Par exemple, si vous avez une variable cityname qui peut prendre les valeurs Cambridge, Somerville ou Allston, et que vous écrivez tab cityname, gen(city), vous obtenez 3 nouvelles variables numériques (city1, city2, city3). City1 sera égale à 1 pour les ménages d’Allston et à 0 dans les autres cas, city2 sera égale à 1 pour les ménages de Cambridge et à 0 dans les autres cas, et ainsi de suite. Notez que les variables indicatrices sont créées dans l’ordre alphabétique.
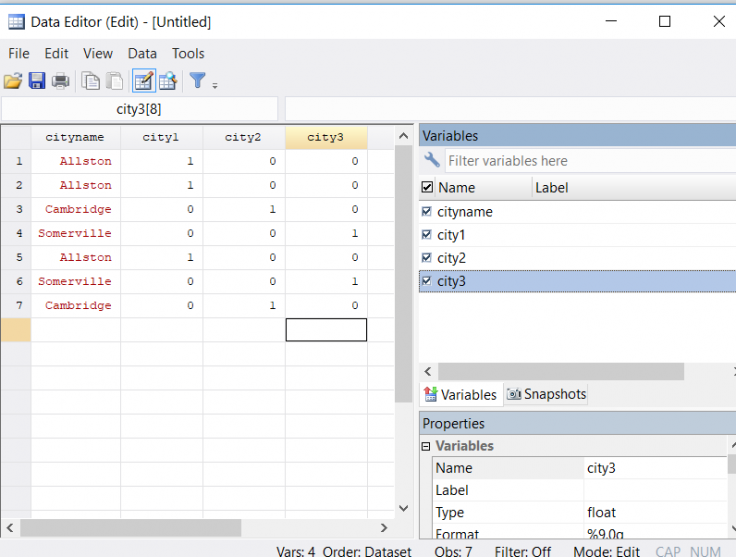
- Remplacez les caractères dans les valeurs de la variable de chaîne en utilisant la commande subinstr (avec les paramètres s, n1, n2 & n3), où s est une chaîne de caractères ou un nom de variable, n1 est ce que vous souhaitez remplacer, n2 est ce par quoi vous souhaitez que n1 soit remplacé, et n3 est le nombre d’occurrences de n1 que vous souhaitez remplacer (utilisez un point (.) dans n3 pour remplacer toutes les occurrences de n1). Notez que si vous n’utilisez pas de point dans n3, les n3 premières occurrences de n1 seront remplacées. Si, pour une raison quelconque, vous ne souhaitez pas remplacer toutes les occurrences, veillez à commencer par trier vos données afin d’en garantir la reproductibilité.
- Vous pouvez également utiliser subinstr soit pour générer de nouvelles variables de chaîne, soit pour remplacer une variable de chaîne.
- La fonction sub-string de Stata (avec les paramètres s, n1, & n2) permet d’extraire les caractères d’une chaîne s à partir du caractère numéro n1 et en continuant sur n2 caractères. Par exemple, si vous avez une variable intitulée doctor_name et que, plutôt que d’écrire le nom de famille du médecin, les enquêteurs ont saisi « Dr. Name1 », « Dr. Name2 », etc., vous pouvez insérer un « . » à la place de la série de caractères commençant au caractère numéro 1 et continuant sur 4 caractères afin de produire une nouvelle chaîne de caractères simplement composée de « Name1 », « Name2 », etc.
L’option « Autre » dans les variables catégorielles
Même si le questionnaire a fait l’objet d’un pilotage approfondi, il peut arriver que les options de réponse proposées pour une variable catégorielle ne soient pas exhaustives et que les répondants choisissent donc l’option « autre » (une nouvelle variable de chaîne est alors créée pour les réponses « autre » de cette variable particulière). Par exemple, une liste des membres du ménage incluant le lien de parenté avec le chef de ménage peut ne pas inclure les arrière-grands-parents, qui apparaissent pourtant dans le cadre de l’enquête, ou bien les répondants peuvent déclarer leurs ventes de maïs dans une unité de mesure non standard que vous n’avez pas incluse (par exemple des seaux de 5 litres). Dans ce type de cas, vous devez :
- Essayer de standardiser les options « autre » dans la mesure du possible en utilisant des outils de manipulation des chaînes de caractères.
- Si une même réponse « autre » apparaît à de nombreuses reprises (par exemple, si de nombreux ménages ont inclus un arrière-grand-parent dans leur liste), envisagez d’ajouter une nouvelle valeur à la variable catégorielle principale pour cette option « autre ». Si vous décidez de procéder ainsi, veillez à documenter cette opération en mettant à jour les libellés de valeur de la variable, le questionnaire et le livre de code, ainsi que vos commentaires sur le nettoyage des données.
- Pour mettre à jour les libellés de valeur, utilisez la commande label define…, add. Par exemple, label define relationship 7 “great grandparent”, add permet d’ajouter « great grandparent » (arrière-grand-parent) à l’ensemble des libellés de lien de parenté précédemment définis.
- Cela vous sera utile si vous souhaitez utiliser cette variable dans le cadre de l’analyse, car il n’est pas possible d’utiliser des chaînes de caractères dans une régression. Il est possible, par exemple, que vous souhaitiez étudier la répartition intergénérationnelle au sein du ménage, et que vous vouliez soit regrouper les arrière-grands-parents avec les grands-parents, soit étudier séparément les arrière-grands-parents si vous en avez suffisamment.
Dernier point important
Documentez de manière exhaustive toutes les décisions que vous prenez et veillez à ce qu’elles soient toujours réversibles (en créant éventuellement une nouvelle variable). Par exemple, HH_income_annual par rapport à HH_income_annual_corrected.
Libellés
- Nommez les variables de manière explicite et attribuez-leur un libellé. Exemple : n’utilisez pas var150b si vous pouvez utiliser HH_Income_annual.
- Pour faciliter cette tâche, vous pouvez choisir les noms de variables et les libellés proposés par SurveyCTO, ce qui vous permettra de gagner du temps :
- Dans l’onglet survey, le nom des variables apparaît dans la colonne name (voir l’image 1 ci-dessous, ainsi que la ressource sur la programmation des enquêtes pour plus de ressources sur la programmation dans SurveyCTO).
- Si nécessaire, utilisez la commande rename variable sous Stata.
- Utilisez un même préfixe pour les variables apparentées (par exemple, hh_varname pour toutes les variables relatives aux ménages, dist_varname pour les variables au niveau du district, etc.). Cette méthode de dénomination facilite la création de boucles et permet de résumer plus rapidement les variables (par exemple, summarize hh_* permet de résumer toutes les variables au niveau des ménages).
- Pour faciliter cette tâche, vous pouvez choisir les noms de variables et les libellés proposés par SurveyCTO, ce qui vous permettra de gagner du temps :
- Toutes les variables de l’ensemble de données nettoyé doivent être accompagnées d’un libellé les décrivant. Par exemple, la variable HH_Income_annual doit être accompagnée du libellé « Revenu annuel du ménage (KSH) ».
- Dans SurveyCTO, cette opération s’effectue dans les onglets survey et choices (voir images 1 et 2 ci-dessous, respectivement).
- Dans l’onglet survey, le type doit être select_one, suivi du nom du libellé
- Dans l’onglet choices, le nom de la valeur figure dans la colonne list_name. Les valeurs numériques associées aux options de réponse se trouvent dans la colonne value, et les libellés correspondants dans la colonne label.
- Dans SurveyCTO, cette opération s’effectue dans les onglets survey et choices (voir images 1 et 2 ci-dessous, respectivement).
- Variables catégorielles : Attribuez un libellé à toutes les catégories/valeurs possibles de la variable.
- Pour les variables binaires, (re)codez la variable de manière à ce que 1 corresponde à l’affirmative (par exemple, 1=Oui, 0=Non). Il arrive que le « non » reçoive le code 2, ce qui peut poser problème lors de l’analyse (par exemple, reg outcome treatment – le coefficient associé à la variable de traitement n’est pas facile à interpréter si 1=groupe de traitement et 2=groupe témoin). Pour éviter ce type de problème, recodez « non » en 0 au moment du nettoyage des données.
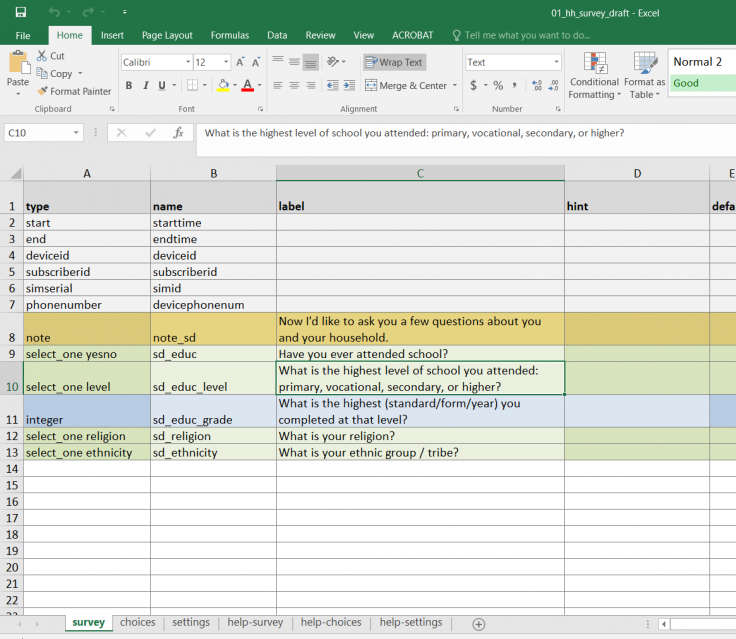
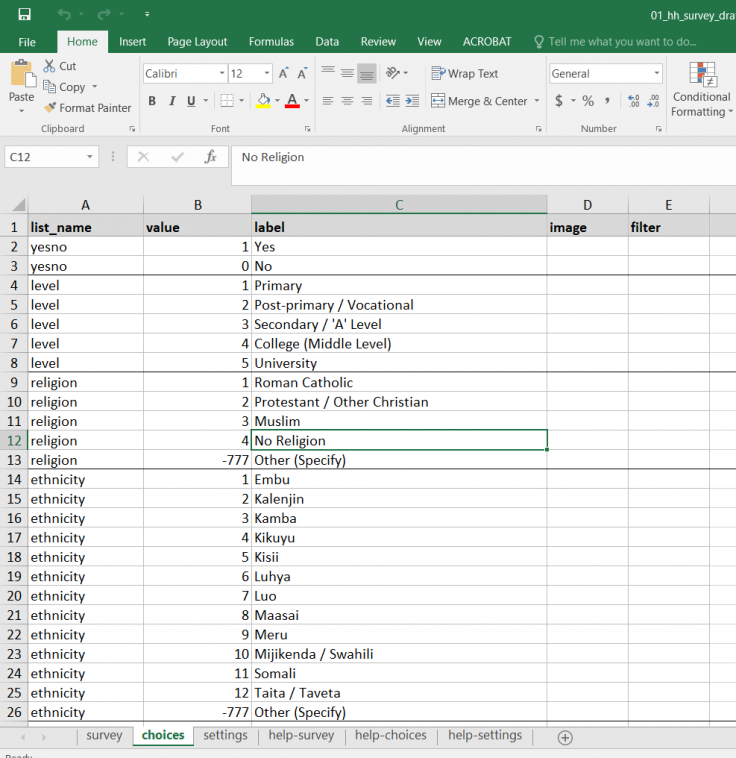
Noms et libellés des variables et des valeurs dans SurveyCTO
Dernière modification : février 2020.
Ces ressources sont le fruit d’un travail collaboratif. Si vous constatez un dysfonctionnement, ou si vous souhaitez suggérer l’ajout de nouveaux contenus, veuillez remplir ce formulaire.
Nous tenons à remercier Lars Vilhuber, Maya Duru, Jack Cavanagh, Aileen Devlin, Louise Geraghty, Sam Ayers et Rose Burnam pour leurs commentaires précieux. Ce document a été relu et corrigé par Chloe Lesieur, et traduit de l’anglais par Marion Beaujard. Toute erreur est de notre fait.
Additional Resources
Reproducible Research: Best Practices for Data and Code Management, IPA
Kluender, Raymond et Benjamin Marx. Programming with Stata. IAP Skills Workshops. 26 janvier 2016.
Manuel Stata : Coding times and dates
Manuel Stata : Erase a Disk File
Manuel Stata : Logging your session
Manuel Stata : mvencode
Manuel Stata : Reshaping data
Manuel Stata : trace
Manuel Stata : String functions
UCLA's Stata Learning Modules: Reshaping data wide to long
Modules d’apprentissage de Stata : Reshaping data wide to long
Modules d’apprentissage de Stata : Reshaping data long to wide
String Functions
UCLA sur l’Imputation Multiple sous Stata
Dropbox: File Version History Overview
GitHub Help: Set Up Git
Présentation Introduction to GitHub tirée de la formation de J-PAL pour le personnel de recherche (ressource interne de J-PAL)
Open Office: Subversion Basics SVN
Formation Version Control with Git d’Udacity
MIT Data Management Services‘s Managing your data – Project Start & End Checklists
University of Minnesota Libraries’ Creating a Data Management Plan
IPA's Cleaning guide
IPA's Reproducible research: Best practices for data and code management
IPA's Standard missing values (see the link on page 6)
Présentation Coding Best Practices tirée de la formation de J-PAL pour le personnel de recherche (ressource interne de J-PAL)
Julian Reif's Stata coding guide
Blog de Marc Bellemare Metrics Monday: Data cleaning
Blog de Marc Bellemare Metrics Monday: What to do with missing data
MIT School of Engineering: Can a computer generate a truly random number?
Ressource Pseudocode 101 de MITx 6.00.1 (Introduction to Computer Science and Programming Using Python).
The World Bank DIME Wiki: Data cleaning
The World Bank DIME Wiki: Data cleaning checklist
References
Gentzkow, Matthew and Jesse M. Shapiro. 2014. Code and Data for the Social Sciences: A Practitioner’s Guide. University of Chicago mimeo, http://faculty.chicagobooth.edu/matthew.gentzkow/research/CodeAndData.pdf, last updated January 2014.