




Les composantes d’une évaluation aléatoire
Summary
Cette ressource propose un aperçu général des différentes étapes dont se compose une évaluation aléatoire, et présente en parallèle une sélection d’outils pédagogiques conçus dans le cadre de nos activités de renforcement des capacités en ligne et en présentiel. Dans ce document, le lecteur trouvera des ressources écrites, des conférences vidéo et des études de cas abordant différents aspects des évaluations aléatoires, issues de nos programmes de formation professionnelle, et en particulier de la formation Evaluating Social Programs (L’évaluation des programmes sociaux). Pour avoir accès à d’autres documents de ce type, veuillez consulter nos ressources pédagogiques.
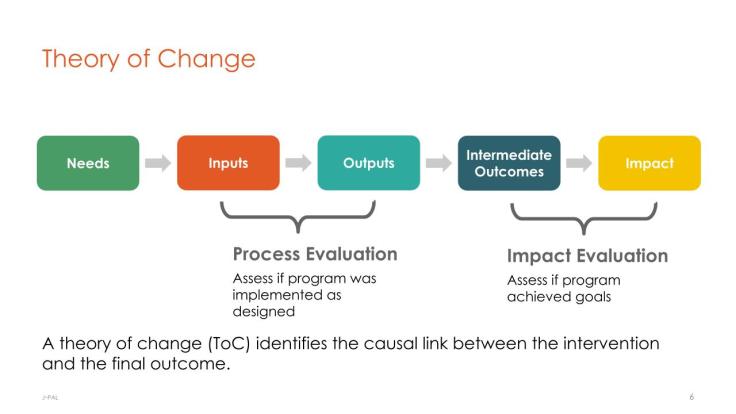
1. Théorie du changement
La première étape d’une évaluation consiste à réexaminer les objectifs du programme et à revoir la façon dont on envisage de les atteindre. Pour faciliter cette tâche, on peut avoir recours à un cadre logique ou à un modèle de théorie du changement, en s’appuyant éventuellement sur d’autres outils issus du cadre de suivi et d’évaluation, comme une évaluation des besoins (approche systématique permettant d’identifier la nature et la portée d’un problème social) ou une évaluation de la théorie qui sous-tend le programme (élaboration d’une théorie du fonctionnement du programme et description des étapes logiques grâce auxquelles la politique proposée va répondre au besoin identifié). Les chercheurs doivent ensuite définir avec précision la question de recherche qu’ils souhaitent étudier. Est-il possible de répondre à cette question en testant une relation de causalité ou une hypothèse causale ? Quels sont les éléments qui peuvent être randomisés (par exemple, les bénéficiaires du programme, les acteurs chargés de sa mise en œuvre ou le moment où le programme est mis en œuvre) ? Comment le programme et la théorie du changement cadrent-ils avec la question de recherche ? Quelles données les chercheurs peuvent-ils collecter pour répondre à leur question de recherche ?
Pour plus d’informations sur la théorie du changement, voir notre conférence What is Evaluation et nos études de cas.
2. Mesures
Dans le cadre d’une évaluation aléatoire, les mesures sont généralement effectuées à deux étapes clés : au début de l’étude (baseline), généralement pour recueillir des statistiques descriptives sur l’échantillon d’étude (telles que l’âge moyen, le revenu des ménages ou la composition par sexe), et à la fin de l’étude (endline) pour estimer l’effet de l’intervention. Certaines évaluations aléatoires collectent également des données en milieu d’intervention, aussi appelées données de mi-parcours, qui servent généralement à contrôler la mise en œuvre de l’intervention.
De nombreuses évaluations aléatoires utilisent des enquêtes pour mesurer les résultats. Les chercheurs en sciences sociales collectent souvent des données originales et très spécifiques pour mesurer les variables de résultat précises auxquelles s’intéresse l’évaluation d’impact. Ils peuvent par exemple mesurer la force des préférences individuelles, comme la prise de risque ou le fait de rendre la pareille suite à un geste généreux ; des données précises de localisation ou des données GPS ; des informations relatives au réseau social et aux relations financières au sein d’un village ; la qualité et la quantité de biens achetés et consommés ; l’autonomisation des femmes et des filles ; et bien d’autres choses encore.
Outre les données d’enquête, l’utilisation de données administratives est également de plus en plus courante. Utiliser des données administratives dans le cadre d’une évaluation aléatoire permet aux chercheurs de répondre à des questions très diverses, et ce à un coût relativement faible. Par exemple, des chercheurs de J-PAL ont pu répondre à de nombreuses questions essentielles concernant l’accès à la santé et le financement de la santé chez les ménages à faibles revenus aux États-Unis en utilisant des données issues des programmes Medicare et Medicaid. Les données administratives sont extrêmement utiles, notamment pour assurer le suivi à long terme de l’échantillon d’étude. Pour plus d'informations concernant l’utilisation de ce type de données par J-PAL, voir notre initiative IDEA (Innovations in Data and Experiments in Action).
Kelsey Jack, professeure affiliée à J-PAL, explore ces concepts dans notre formation 2016 sur l’évaluation des programmes sociaux (vidéo ; présentation). J-PAL propose en outre des ressources techniques sur les mesures et la conception des enquêtes. Vous trouverez ci-dessous quelques évaluations réalisées par des chercheurs affiliés à J-PAL qui utilisent des données administratives pour mesurer les résultats :




Informing Policy with Research in Brazil

3. Choisir un protocole de recherche qui soit éthique, réalisable et fondé sur des bases scientifiques solides
a. Éthique
Dans certains cas, la réalisation d’une évaluation aléatoire peut poser des problèmes éthiques, notamment lorsque l’intervention concerne une prestation à laquelle tout le monde devrait avoir droit, ou lorsque le partenaire chargé de la mise en œuvre dispose des ressources nécessaires pour traiter l’ensemble de l’échantillon d’étude. Le protocole de recherche peut être modifié pour répondre à ces préoccupations. Il est notamment possible de mener une évaluation aléatoire sans restreindre l’accès à l’intervention. Ainsi, comme indiqué dans la ressource Introduction aux évaluations aléatoires, on peut sélectionner aléatoirement certains individus pour les inciter à participer au programme, par exemple en leur envoyant des emails de rappel ou en leur téléphonant, sans pour autant refuser l’accès aux autres participants intéressés par l’intervention. Si le partenaire de mise en œuvre dispose des ressources nécessaires pour traiter l’ensemble de l’échantillon, mais ne sait pas encore si l’intervention est efficace, les chercheurs peuvent utiliser un protocole randomisé de mise en place graduelle afin de traiter dans un premier temps une partie de l’échantillon pour identifier les effets de l’intervention, avant de l’étendre dans un deuxième temps à l’ensemble de l'échantillon.
Pour plus de détails sur les façons dont le protocole de recherche peut permettre de résoudre les problèmes de randomisation, consultez le guide de J-PAL North America intitulé Real-World Challenges to Randomization, notre ressource sur l’éthique ou notre conférence intitulée How to Randomize. Pour plus d’informations sur la rédaction du dossier à soumettre au comité d’éthique (IRB) et sur les exigences légales et institutionnelles à respecter dans le cadre d’une collaboration avec un IRB, voir notre ressource Soumettre un dossier à un comité d’éthique. Pour en savoir plus sur la façon dont les projets de recherche de J-PAL se conforment aux directives éthiques des IRB, veuillez consulter les Protocoles de recherche de J-PAL.
b. Faisabilité
Dans le protocole de randomisation le plus simple, les chercheurs sélectionnent aléatoirement les unités qui vont bénéficier ou non du programme. Si cette solution n’est pas réalisable, comme c’était le cas dans les exemples ci-dessus pour des raisons éthiques, les chercheurs peuvent modifier le protocole, par exemple en randomisant le moment où les groupes vont recevoir le traitement ou encore le prestataire chargé de le mettre en œuvre. Il convient également de noter que le coût et la charge de travail que représentent l’organisation des enquêtes et la mise en œuvre du programme ont nécessairement une incidence sur le protocole et la taille de l’échantillon de l’évaluation aléatoire. La prise en compte de ces facteurs peut modifier le caractère généralisable des résultats de la recherche (voir ci-dessous), mais elle préserve la validité interne des résultats du fait de la randomisation. Pour plus d’informations, consultez le guide de J-PAL North America intitulé Real-World Challenges to Randomization and their Solutions, notre ressource sur la randomisation ou notre conférence How to Randomize.
c. Choisir la taille de l’échantillon
Pour qu’une évaluation soit fiable sur le plan statistique, il faut s’assurer qu’elle dispose d’une bonne puissance statistique. La puissance statistique d’une évaluation détermine la probabilité pour que celle-ci détecte les éventuelles variations de la variable d’intérêt si le programme évalué a effectivement un impact. Les chercheurs effectuent des analyses de puissance afin de prendre un certain nombre de décisions, notamment en ce qui concerne le nombre d’unités à inclure dans l’étude, la proportion d’unités allouées à chaque groupe et le niveau de randomisation (par exemple, l’élève, la classe ou l’école entière). Les calculs de puissance permettent de s’assurer que les chercheurs disposent d’une taille d’échantillon suffisante pour détecter l’effet principal du programme étudié, mais aussi de déterminer si l’effet du programme diffère entre les différents groupes de traitement ou pour différents sous-groupes de la population. Pour écouter Rachel Glennerster, alors Directrice exécutive, aborder les calculs de puissance, voir ci-dessous (présentation ici). J-PAL propose en outre une ressource, un exercice et un guide sur les calculs de puissance.
d. Menaces pour la validité interne
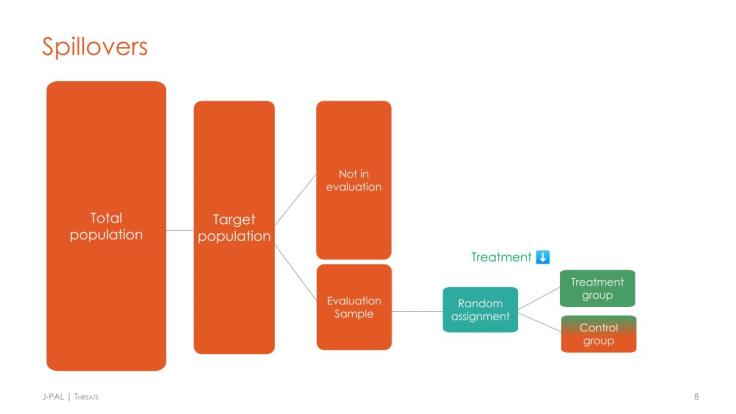
Comme toute méthodologie d’évaluation, les évaluations aléatoires sont exposées à un certain nombre de menaces pour leur validité interne, notamment les effets de diffusion, l’attrition et la non-conformité partielle. Pour garantir la fiabilité statistique de l’étude, les chercheurs peuvent concevoir l’intervention et les procédures de collecte des données de façon à minimiser ou à mesurer ces menaces. Les chercheurs qui s’inquiètent de l’existence de possibles effets de diffusion peuvent ainsi procéder à une randomisation à un niveau plus élevé (par exemple au niveau de l’école plutôt que de l’élève) pour éviter toutes retombées au sein du groupe témoin et mesurer l’effet total dans le groupe de traitement. Ils peuvent aussi moduler la part de la population qui est soumise au traitement au sein d’un village et mesurer les effets de diffusion sur ceux qui n’ont pas été traités. Pour un exercice guidé sur la gestion des menaces et l’analyse des données, voir la section « Threats » de notre conférence intitulée Threats and Analysis, notre étude de cas sur les menaces et l’analyse (intégrée ci-dessous), ou le guide de J-PAL North America intitulé Real-World Challenges to Randomization.
4. Randomisation
Comme son nom l’indique, l’un des principes fondamentaux de l’évaluation aléatoire est l’assignation aléatoire des unités au groupe de traitement ou au groupe témoin. Les chercheurs ont à leur disposition tout un éventail de modèles de randomisation, allant de la randomisation simple, où toutes les unités ont les mêmes chances de recevoir le traitement, à la randomisation stratifiée, plus complexe, où les unités sont réparties en groupes (appelés blocs ou strates), puis randomisées au sein de chaque strate (par exemple, une étude stratifiée par sexe effectuera une randomisation parmi les hommes de l’échantillon et, séparément, une randomisation parmi les femmes de l’échantillon). Une introduction aux différents types de randomisation figure dans notre conférence How to Randomize. Pour plus d’informations à ce sujet, notamment pour comprendre dans quels cas la randomisation stratifiée est nécessaire et pourquoi, ainsi que pour consulter des exemples de lignes de code permettant d’effectuer une randomisation, nous vous invitons à consulter notre ressource sur la randomisation.
5. Analyse des données
Dans sa forme la plus simple, l’analyse d’une évaluation aléatoire utilise les données de fin d’étude pour comparer les résultats moyens du groupe de traitement avec ceux du groupe témoin au terme de l’intervention. La différence mesurée correspond à l’impact du programme. Pour déterminer si cet impact est statistiquement significatif, les chercheurs peuvent comparer les moyennes à l’aide d’un simple test de Student. Ainsi, l’un des nombreux avantages de l’évaluation aléatoire tient au fait qu’elle permet de mesurer l’impact sans avoir recours à des techniques statistiques avancées. Il est néanmoins possible d’effectuer des analyses plus complexes, notamment des régressions qui augmentent le degré de précision en tenant compte des caractéristiques de la population étudiée qui sont susceptibles d’être corrélées avec les variables de résultat.
Une introduction à l’analyse des données, y compris en présence de menaces pour la validité interne, est proposée dans la section « Analysis » de notre conférence intitulée Threats and Analysis (voir également la présentation et l’étude de cas). Notre ressource Analyse des données, plus technique, couvre des sujets tels que l’analyse de sous-groupes, la vérification d’hypothèses multiples et les différents types d’effets de traitement. Elle inclut également des exemples de code, comme celui présenté ci-dessous :
tempfile tempfilename
save `tempfilename'
/* this can then be used as any other dataset,
e.g.,can be merged, appended, etc. *
6. Analyse coût-efficacité
Le calcul du rapport coût-efficacité d’un programme (par exemple le montant dépensé par jour supplémentaire de présence d’un élève à l’école) permet d’identifier les programmes qui sont susceptibles d’offrir le meilleur rapport qualité-prix. L’analyse coût-efficacité (ACE) consiste à synthétiser un programme complexe sous la forme d’un simple rapport entre ses coûts et ses effets, offrant ainsi un outil de mesure commun pour comparer des programmes mis en œuvre dans différents contextes historiques et géographiques. À elle seule, l’analyse coût-efficacité ne fournit pas suffisamment d’informations pour aiguiller tous les choix en matière de politique ou d’investissement, mais elle constitue un point de départ utile pour choisir entre différents programmes visant à atteindre le même objectif. Pour réaliser une telle analyse, il faut disposer de deux données : une estimation de l’impact du programme et le coût de celui-ci. Afin d’aider d’autres organisations à réaliser ce type d’analyse, J-PAL a mis au point des recommandations et des modèles pour l’évaluation des coûts.
7. Généralisation
Contrairement à la validité interne, qu’une évaluation aléatoire bien exécutée peut garantir, la validité externe, ou généralisabilité, est plus difficile à atteindre. Pour répondre à ce défi de la généralisation, J-PAL a élaboré un cadre pratique qui décompose une grande question – « ce programme va-t-il fonctionner ici ? » – en une série de questions plus précises, ancrées dans la théorie qui sous-tend le programme. Pour plus d’informations, voir notre conférence (présentation) ou notre article sur le cadre de généralisation.
Des travaux récents menés par des professeurs affiliés à J-PAL explorent les difficultés inhérentes au fait de chercher à tirer des conclusions d’une évaluation aléatoire locale en procédant à une étude de cas du programme Teaching at the Right Level (TaRL). Ce programme a été expérimenté dans des contextes variés, auprès de populations diverses, avec plusieurs modèles de mise en œuvre et différents partenaires, afin d’en tester les mécanismes et d’apporter une première réponse aux questions relatives à la généralisation des résultats. La taille de la population étudiée peut avoir une influence sur le caractère généralisable des résultats (Muralidharan & Niehaus 2017). Pour en savoir plus sur la façon dont les données probantes issues d’un contexte donné peuvent servir de base à des politiques dans d’autres contextes, voir la page Des résultats aux politiques sur le site de J-PAL.
En publiant les données issues de leurs évaluations, les chercheurs peuvent apporter un éclairage supplémentaire sur les questions relatives à la validité externe et au caractère généralisable des résultats. Ces dix dernières années, le nombre d’organismes de financement, de revues scientifiques et d’organismes de recherche qui ont adopté des politiques de partage des données a considérablement augmenté. Lorsque l’American Economic Association a adopté sa première politique de ce type en 2005, elle était l’une des premières revues de sciences sociales à exiger que les données soient publiées en même temps que l’article de recherche. Aujourd’hui, de nombreuses revues scientifiques de premier plan en économie et en sciences sociales exigent la publication des données. De même, de nombreuses fondations et institutions gouvernementales, telles que la Fondation Bill et Melinda Gates1, la National Science Foundation2 et les National Institutes of Health, ont mis en place des politiques de ce type. En sa qualité d’organisme de financement et de recherche, J-PAL a adopté en 2015 une politique de publication des données qui s’applique à tous les projets de recherche qu’il finance ou met en œuvre.3 J-PAL a par ailleurs créé des guides sur la désidentification et la publication des données afin d’aider les équipes de recherche à réfléchir aux étapes nécessaires à la publication de leurs données scientifiques.
Dernière modification : juillet 2020.
Ces ressources sont le fruit d’un travail collaboratif. Si vous constatez un dysfonctionnement, ou si vous souhaitez suggérer l'ajout de nouveaux contenus, veuillez remplir ce formulaire.
Ce document a été traduit de l’anglais par Marion Beaujard.
Nous remercions Rohit Naimpally pour ses commentaires précieux. Ce document a été relu et corrigé par Evan Williams, et traduit de l’anglais par Marion Beaujard. Toute erreur est de notre fait.
References
Banerjee, Abhijit, Rukmini Banerji, James Berry, Esther Duflo, Harini Kannan, Shobhini Mukerji, Marc Shotland, and Michael Walton. 2017. "From proof of concept to scalable policies: Challenges and solutions, with an application." Journal of Economic Perspectives 31, no. 4: 73-102. https://pubs.aeaweb.org/doi/pdf/10.1257/jep.31.4.73
Muralidharan, Karthik, and Paul Niehaus. 2017. "Experimentation at scale." Journal of Economic Perspectives 31, no. 4 (2017): 103-124. https://www.aeaweb.org/articles?id=10.1257/jep.31.4.103