





Introduction aux évaluations aléatoires
Summary
Cette ressource propose une présentation générale et non technique des évaluations aléatoires. Ce type d’évaluation est notamment utilisé dans le cadre de recherches visant à mesurer l’impact de politiques publiques : à ce jour, les chercheurs affiliés à J-PAL ont ainsi mené plus de 1000 évaluations aléatoires portant sur des politiques relevant de dix secteurs thématiques dans plus de 80 pays. Le présent document met en lumière des travaux réalisés dans des contextes variés, notamment des études sur le chômage des jeunes à Chicago ainsi que des programmes de subvention du riz en Indonésie et de transfert monétaire conditionnel au Mexique. Elle indique dans quels cas les évaluations aléatoires s’avèrent particulièrement utiles, et aborde également les situations où elles ne sont pas la méthode d’évaluation la plus adaptée.
Introduction
Ces dernières années, les évaluations aléatoires, ou essais contrôlés randomisés (ECR), ont pris une place de plus en plus importante en tant qu’outil de mesure de l’impact des politiques publiques. Le prix Nobel d’économie 2019, décerné aux co-fondateurs de J-PAL, Abhijit Banerjee et Esther Duflo, ainsi qu’à Michael Kremer, chercheur affilié de longue date à J-PAL, a récompensé la manière dont cette méthode de recherche a révolutionné le domaine des politiques sociales et du développement économique.
Les évaluations aléatoires sont une méthode d’évaluation de l’impact. Dans ce type d’étude, les participants sont répartis aléatoirement entre, d’une part, un ou plusieurs groupes recevant un ou plusieurs types d’intervention, ou « groupe(s) de traitement », et, d’autre part, un groupe témoin qui ne reçoit aucune intervention. Les chercheurs mesurent ensuite les variables d’intérêt dans le(s) groupe(s) de traitement et le groupe témoin. Les évaluations aléatoires permettent d’obtenir une estimation rigoureuse et non biaisée de l’impact causal d’une intervention ; en d’autres termes, de déterminer quels changements spécifiques dans la vie des participants peuvent être attribués au programme. Elles permettent également aux chercheurs et aux décideurs politiques d’adapter leurs protocoles de recherche afin de répondre à des questions spécifiques concernant l’efficacité d’un programme et la théorie du changement sur laquelle il repose. Si elle est conçue et mise en œuvre de manière consciencieuse, une évaluation aléatoire peut permettre de répondre à des questions telles que : dans quelle mesure ce programme a-t-il été efficace ? A-t-il eu des effets secondaires imprévus ? Quels en ont été les principaux bénéficiaires ? Quelles composantes du programme fonctionnent, et lesquelles ne fonctionnent pas ? Quel est le rapport coût-efficacité du programme ? Comment se situe-t-il par rapport à d’autres programmes conçus pour atteindre des objectifs similaires ?
Le réseau de chercheurs de J-PAL travaille en étroite collaboration avec les gouvernements, les ONG, les donateurs et les autres partenaires qui souhaitent mettre en œuvre une évaluation aléatoire pour répondre à toutes ces questions
Les évaluations aléatoires en pratique
Les évaluations aléatoires peuvent permettre de répondre à des questions de politique publique qui sont susceptibles d’avoir une incidence sur la vie de millions de personnes. Par exemple, un programme indonésien intitulé Raskin (aujourd’hui rebaptisé Rastra), qui consistait à fournir du riz subventionné aux ménages à faible revenu, a permis de toucher 17,5 millions de personnes en 2012. Cependant, des chercheurs ont estimé que, du fait de problèmes de corruption et d’inefficacité, les ménages éligibles ne recevaient qu’environ un tiers des avantages auxquels ils avaient droit.
Une évaluation aléatoire a donc été réalisée par Banerjee et al. (2018)[!1] afin de déterminer si le fait de munir les ménages de cartes d’identification indiquant clairement les prestations auxquelles ils avaient droit et les règles du programme faciliterait leur accès à l’intervention. Si ces cartes Raskin fonctionnaient, les ménages défavorisés bénéficieraient de prestations supplémentaires ; dans le cas contraire, le programme serait une perte d’argent. Dans un scénario idéal, il aurait fallu que les chercheurs puissent distribuer des cartes Raskin et mesurer les avantages qu’en retirait chaque ménage, puis remonter le temps pour voir ce qu’il serait advenu de ces mêmes ménages si les cartes ne leur avaient pas été distribuées. Une telle approche leur permettrait de mesurer avec précision l’effet des cartes.
S’il est malheureusement impossible de voyager dans le temps, la randomisation permet d’atteindre un objectif similaire. Dans l’étude qui nous intéresse ici, les chercheurs ont réparti aléatoirement un grand nombre de villages entre l’une des deux versions de l’intervention (les groupes de traitement) et un groupe témoin. Dans son sens le plus simple, l’assignation aléatoire signifie tout simplement que l’on a recours à un mécanisme basé sur le hasard (comme un tirage à pile ou face, un lancer de dé ou un tirage au sort) pour déterminer auquel de ces trois groupes chacun des villages va être assigné.
L’assignation aléatoire à un groupe de traitement ou à un groupe témoin est l’élément central de toute évaluation aléatoire. La plupart des détails techniques relatifs à la création de groupes de traitement et de groupes témoin par assignation aléatoire sont abordés dans notre ressource sur la randomisation.
Une estimation crédible de l’impact
Les évaluations aléatoires présentent un avantage important : elles permettent de s’assurer que les différences observées au niveau des variables de résultat ne sont pas liées à l’existence de différences systématiques entre les groupes. En d’autres termes, toute différence entre les variables de résultat peut raisonnablement être attribuée à l’intervention plutôt qu’à d’autres facteurs.
Dans l’exemple que nous venons de citer, imaginons que ce soit les fonctionnaires chargés de la mise en œuvre du programme qui choisissent quels ménages vont se voir remettre une carte. Les fonctionnaires qui ne respectent pas les règles du programme ou qui supervisent des opérations de distribution inefficaces préféreront peut-être éviter que leurs administrés reçoivent davantage d’informations sur le programme et seront donc moins enclins à inscrire leur communauté. Dans ce cas, les communautés où la distribution du riz est caractérisée par le plus grand nombre d’irrégularités ne recevront pas de cartes, tandis que les communautés où le programme Raskin fonctionne déjà bien en recevront. On risque par conséquent de surestimer l’impact de l’intervention.
L’assignation aléatoire résout ce problème de sélection en garantissant que le groupe de traitement et le groupe témoin sont comparables. Bien entendu, il se peut malgré tout que les deux groupes ne soient pas parfaitement identiques. En effet, deux villages affectés respectivement au groupe de traitement et au groupe témoin ont toutes les chances d’être différents, provoquant ainsi des variations fortuites entre les différents groupes. Toutefois, à mesure que l’on ajoute des observations (dans notre exemple, des villages), les deux groupes se ressemblent de plus en plus, et ressemblent de plus en plus à la population dont ils sont issus. Les méthodes statistiques permettent alors d’évaluer la probabilité pour que les différences de résultats observées à l’issue de l’intervention soient dues au programme évalué. Si l’échantillon est suffisamment grand, il est ainsi possible de déterminer l’effet réel de l’intervention de façon très fiable.
À quels types de questions une évaluation aléatoire permet-elle de répondre ?
Les évaluations aléatoires sont particulièrement adaptées pour évaluer le fonctionnement d’un programme social en conditions réelles. Elles se concentrent souvent sur les comportements humains et les réactions des participants à la mise en œuvre d’un programme.
Prenons l’exemple théorique d’un programme de distribution d’eau dans une région où les sources d’eau sont contaminées. Comment savoir si ce programme atteint bien son objectif de réduction de la morbidité et de la mortalité ? Ce n’est pas la même chose que de poser une question relevant de la recherche scientifique en laboratoire, comme « L’exposition au plomb affecte-t-elle le fonctionnement des reins ? » ou « Quelles toxines ingère-t-on lorsqu’on utilise de l’eau non filtrée pour cuisiner ? ». Pour répondre à ce type de questions, on aura plutôt recours à des expériences en laboratoire ou à une étude clinique contrôlée. Ce n’est pas non plus la même chose que de se demander si un programme est correctement mis en œuvre, et notamment si les étapes nécessaires à son bon fonctionnement sont bien respectées. La meilleure façon de répondre à ce type de questions est de mettre en place un contrôle minutieux des processus.
Il existe toutefois un élément clé qui ne peut pas être testé en laboratoire, ni contrôlé par les responsables de la mise en œuvre : il s’agit de la façon dont les ménages vont réagir lorsque l’eau leur sera livrée et qu’on leur demandera de l’utiliser pour cuisiner, boire et se laver. Il faut qu’ils consomment l’eau filtrée et chlorée de façon systématique, même si les aliments ont un goût différent et que le processus peut nécessiter la manipulation de lourds récipients d’eau. Il faut également qu’ils cessent de consommer de l’eau non traitée ou de s’exposer à d’autres sources de toxines, même s’ils ont l’habitude de fréquenter une laverie voisine ou de grignoter des fruits rapidement rincés au robinet.2 Dans tous ces contextes, une évaluation du programme peut permettre de déterminer si les comportements des individus ont été modifiés avec succès, et si les objectifs de l’intervention sont donc atteints.
Afin d’obtenir une estimation non biaisée de l’impact réel d’un programme, il est généralement préférable que l’intervention soit déployée au sein du groupe de traitement dans des conditions aussi proches que possible de l’intervention réelle, en s’appuyant sur une collaboration étroite entre les chercheurs et les organismes chargés de la mise en œuvre du programme. Toutefois, afin de mieux comprendre les mécanismes sous-jacents, comme les facteurs comportementaux mentionnés ci-dessus, les chercheurs peuvent décider de tester directement la composante liée au comportement humain, sans mettre en œuvre l’intégralité du programme. Pour ce faire, on peut par exemple envisager de mettre en place un système de distribution temporaire (et peut-être, dans un premier temps, moins efficace) pour fournir de l’eau aux ménages du groupe de traitement, pour les seuls besoins de l’évaluation.
Les évaluations aléatoires présentent également un autre avantage majeur, celui de permettre aux chercheurs d’adapter l’intervention et la collecte de données pour répondre à des questions spécifiques. Par exemple, on peut avoir besoin de comprendre l’impact individuel des différentes composantes d’un programme et leurs mécanismes de fonctionnement respectifs.
Dans le cas du projet Raskin, les chercheurs ont expérimenté deux variantes du système de carte d’identification, en créant notamment un groupe de traitement pour déterminer si le fait de fournir des informations sur le prix officiel du riz subventionné avait un impact supplémentaire sur la quantité de riz que les ménages éligibles recevaient et sur le prix qu’ils payaient. Ils ont constaté que les ménages qui avaient reçu ces informations sur la tarification n’avaient pas payé moins cher, mais avaient reçu de plus grandes quantités de riz subventionné. Ces résultats suggèrent que le fait d’être informés des prix a renforcé le pouvoir de négociation des ménages auprès des fonctionnaires locaux, dont certains surfacturaient le riz avant la mise en place des cartes. C’est en partie sur la base de ces résultats que le gouvernement a ensuite décidé d’étendre l’utilisation des cartes d’identification des bénéficiaires de l’aide sociale à 15,5 millions de ménages dans tout le pays, touchant ainsi plus de 65 millions de personnes en 2013.
Les évaluations aléatoires peuvent également être utilisées pour comprendre les effets à long terme d’une intervention.3 Prenons une nouvelle fois l’exemple du projet Raskin : à court terme, le fait de recevoir de plus grandes quantités de riz doit en théorie améliorer la nutrition des membres du ménage, ce qui peut potentiellement réduire leur nombre de jours d’absence à l’école ou augmenter leur nombre d’heures de travail. Au fil du temps, ces effets secondaires à court terme peuvent se traduire par une augmentation du nombre d’années de scolarité ou une hausse des salaires. La mesure des effets à long terme se heurte cependant à un certain nombre de difficultés : avec le temps, il y a notamment de grands risques pour que des facteurs externes à l’étude aient affecté les participants, et les chercheurs peuvent aussi avoir du mal à localiser ces derniers. Toutefois, grâce à un suivi régulier et à la mesure des résultats intermédiaires, le protocole randomisé du programme Raskin permet d’estimer avec fiabilité les effets du traitement à long terme. Pour plus d’informations, voir l’article de Bouguen et al. (2018) intitulé Using RCTs to Estimate Long-Run Impacts in Development Economics.
Les données administratives peuvent s’avérer particulièrement utiles pour mesurer les effets à long terme. À titre d’exemple, des chercheurs affiliés à J-PAL ont utilisé des données fiscales recueillies par le gouvernement fédéral des États-Unis pour mesurer les effets à long terme du programme Moving to Opportunity (MTO). Ce programme consistait à distribuer aux ménages du groupe de traitement des bons de logement qui ne pouvaient être utilisés que dans les quartiers où le taux de pauvreté était plus faible. À court terme, le programme a eu des résultats mitigés : les chercheurs ont montré que le taux d’emploi et les revenus des adultes du groupe de traitement qui avaient déménagé n’avaient pas augmenté, mais que ceux-ci déclaraient se sentir plus heureux et plus en sécurité dans leur nouveau quartier (Katz et al., 2001). Cependant, en utilisant des données administratives pour analyser les conséquences du programme vingt ans après l’intervention initiale, les chercheurs ont constaté que les enfants des ménages traités qui avaient déménagé avaient vu, une fois adultes, leur situation s’améliorer dans toute une série de domaines par rapport aux enfants des familles du groupe témoin. À l’âge adulte, ils avaient notamment des revenus plus élevés, étaient plus susceptibles de faire des études supérieures et moins susceptibles de vivre dans des quartiers où le taux de pauvreté était plus élevé (Chetty et al., 2016).
Dans le cadre d’une autre évaluation menée en Inde, des chercheurs affiliés à J-PAL ont effectué des enquêtes régulières auprès des bénéficiaires du programme Targeting the Ultra Poor (TUP) afin d’en identifier les effets à long terme et certains des mécanismes de fonctionnement potentiels.4 L’une des principales composantes du programme TUP consiste à remettre aux ménages bénéficiaires des biens de production, comme du bétail. Les effets à court terme du programme (hausse de la consommation, de la richesse et du revenu des ménages) se sont accentués chaque année au cours des sept premières années qui ont suivi la mise en œuvre du programme, puis se sont stabilisés entre la 8e et la 10e année. Les chercheurs ont établi que ces effets à long terme étaient en partie dus au fait que les ménages traités avaient utilisé les revenus générés par le bétail ainsi obtenu pour créer de nouvelles entreprises (Banerjee et al., 2020). D’autres exemples d’études évaluant les effets à long terme des programmes sont disponibles sur la page Évaluations de J-PAL.

Les évaluations aléatoires peuvent également être utilisées pour comprendre les effets à long terme d’une intervention.3 Prenons une nouvelle fois l’exemple du projet Raskin : à court terme, le fait de recevoir de plus grandes quantités de riz doit en théorie améliorer la nutrition des membres du ménage, ce qui peut potentiellement réduire leur nombre de jours d’absence à l’école ou augmenter leur nombre d’heures de travail. Au fil du temps, ces effets secondaires à court terme peuvent se traduire par une augmentation du nombre d’années de scolarité ou une hausse des salaires. La mesure des effets à long terme se heurte cependant à un certain nombre de difficultés : avec le temps, il y a notamment de grands risques pour que des facteurs externes à l’étude aient affecté les participants, et les chercheurs peuvent aussi avoir du mal à localiser ces derniers. Toutefois, grâce à un suivi régulier et à la mesure des résultats intermédiaires, le protocole randomisé du programme Raskin permet d’estimer avec fiabilité les effets du traitement à long terme. Pour plus d’informations, voir l’article de Bouguen et al. (2018) intitulé Using RCTs to Estimate Long-Run Impacts in Development Economics.
Les données administratives peuvent s’avérer particulièrement utiles pour mesurer les effets à long terme. À titre d’exemple, des chercheurs affiliés à J-PAL ont utilisé des données fiscales recueillies par le gouvernement fédéral des États-Unis pour mesurer les effets à long terme du programme Moving to Opportunity (MTO). Ce programme consistait à distribuer aux ménages du groupe de traitement des bons de logement qui ne pouvaient être utilisés que dans les quartiers où le taux de pauvreté était plus faible. À court terme, le programme a eu des résultats mitigés : les chercheurs ont montré que le taux d’emploi et les revenus des adultes du groupe de traitement qui avaient déménagé n’avaient pas augmenté, mais que ceux-ci déclaraient se sentir plus heureux et plus en sécurité dans leur nouveau quartier (Katz et al., 2001). Cependant, en utilisant des données administratives pour analyser les conséquences du programme vingt ans après l’intervention initiale, les chercheurs ont constaté que les enfants des ménages traités qui avaient déménagé avaient vu, une fois adultes, leur situation s’améliorer dans toute une série de domaines par rapport aux enfants des familles du groupe témoin. À l’âge adulte, ils avaient notamment des revenus plus élevés, étaient plus susceptibles de faire des études supérieures et moins susceptibles de vivre dans des quartiers où le taux de pauvreté était plus élevé (Chetty et al., 2016).
Dans le cadre d’une autre évaluation menée en Inde, des chercheurs affiliés à J-PAL ont effectué des enquêtes régulières auprès des bénéficiaires du programme Targeting the Ultra Poor (TUP) afin d’en identifier les effets à long terme et certains des mécanismes de fonctionnement potentiels.4 L’une des principales composantes du programme TUP consiste à remettre aux ménages bénéficiaires des biens de production, comme du bétail. Les effets à court terme du programme (hausse de la consommation, de la richesse et du revenu des ménages) se sont accentués chaque année au cours des sept premières années qui ont suivi la mise en œuvre du programme, puis se sont stabilisés entre la 8e et la 10e année. Les chercheurs ont établi que ces effets à long terme étaient en partie dus au fait que les ménages traités avaient utilisé les revenus générés par le bétail ainsi obtenu pour créer de nouvelles entreprises (Banerjee et al., 2020). D’autres exemples d’études évaluant les effets à long terme des programmes sont disponibles sur la page Évaluations de J-PAL.
Dans quels cas l’évaluation aléatoire est-elle un outil adapté ?
Exploiter les fenêtres d’action
L’évaluation rigoureuse d’un programme ou d’une politique est particulièrement utile lorsqu’elle est réalisée au bon moment pour avoir une influence sur les décisions politiques.
Prenons l’exemple du Mexique, pays qui a connu une croissance économique régulière et qui est aujourd’hui une économie à revenu intermédiaire de la tranche supérieure, même si le niveau d’inégalité y reste élevé. Dans le but de stimuler leur développement économique, de nombreux pays ont entrepris de mettre en œuvre des programmes nationaux de protection sociale, et le Mexique ne fait pas exception à la règle. Le programme mexicain PROGRESA (plus tard rebaptisé Oportunidades, puis PROSPERA), dispositif de transferts monétaires conditionnels lancé en 1997, est un exemple d’évaluation aléatoire qui, réalisée au bon moment, a pu avoir un impact durable sur les politiques publiques. Cette politique consistait à verser aux mères des allocations en espèces pour leur famille à condition qu’elles veillent à ce que leurs enfants aillent régulièrement à l’école et reçoivent les vaccinations prévues. Ce qui rend le programme PROGRESA remarquable, c’est notamment le fait que son évaluation aléatoire externe lui a permis de survivre à un changement de leadership politique lors des élections présidentielles de 2000. Ayant anticipé la possibilité d’un démantèlement des programmes sociaux en vigueur, le président de l’époque, Ernesto Zedillo, avait lancé l’évaluation afin de dépolitiser la décision concernant PROGRESA et de démontrer qu’il s’agissait d’une politique efficace pour améliorer la situation des enfants en matière de santé et d’éducation (Behrman, 2007).
PROGRESA a d’abord été introduit sous forme de projet pilote dans les zones rurales de sept États. Sur les 506 communautés échantillonnées par le gouvernement mexicain pour le projet pilote, 320 ont été affectées aléatoirement au groupe de traitement et 186 au groupe témoin. Suite à l’intervention, les enfants du groupe de traitement restaient scolarisés plus longtemps et étaient en meilleure santé (en termes de croissance et de taux d’incidence des maladies) que les enfants du groupe témoin (Gertler et Boyce, 2003). Sur la base de ces résultats, le nouveau gouvernement a largement développé le programme en l’étendant aux zones urbaines, et l’initiative a très vite été reproduite dans d’autres pays, comme le Nicaragua, l’Équateur et le Honduras. À l’instar du Mexique, ces pays ont mené des études pilotes pour évaluer l’impact de programmes similaires à PROGRESA sur leur population avant de les généraliser. En 2014, 52 pays avaient mis en œuvre des programmes similaires à PROGRESA (Lamanna, 2014).
À l’inverse, les évaluations aléatoires ne sont pas forcément un outil adapté lorsque des facteurs externes sont susceptibles d’interférer avec le programme au cours de l’évaluation, ou lorsque le programme est modifié de façon significative dans le contexte de l’évaluation.
Contrairement aux expériences menées en laboratoire, les évaluations aléatoires de politiques publiques se déroulent dans des conditions qui ne sont pas isolées des facteurs environnementaux, politiques et économiques. Il peut donc arriver que la manifestation de facteurs externes vienne ébranler notre confiance dans le caractère généralisable ou transposable des résultats de nos recherches. Par exemple, évaluer l’impact d’un programme de microfinance ou de perfectionnement de la main-d’œuvre dans un contexte de récession économique majeure risque de fausser les résultats de l’étude de façon significative. Une évolution du contexte politique peut également compliquer la mise en œuvre d’une évaluation aléatoire, par exemple si les représentants du gouvernement refusent de s’engager à ne pas modifier le programme ou si une ONG met en place un programme similaire à l’intervention étudiée et en fait bénéficier le groupe témoin alors que l’évaluation est en cours. Tous ces facteurs doivent être pris en compte pendant la phase de planification de l’évaluation aléatoire.
Informer les décisions concernant la généralisation et la conception du programme
Une évaluation aléatoire peut s’avérer particulièrement utile lorsque des ressources considérables sont investies dans un nouveau programme mais que l’on ne dispose pas encore de données probantes concernant son impact.
Dans un tel contexte, l’évaluation aléatoire peut venir éclairer les décisions relatives à l’éventuelle généralisation du programme. Prenons l’exemple du programme One Summer Chicago Plus (OSC+), qui fonctionne en collaboration avec des organismes communautaires locaux pour offrir aux jeunes des emplois d’été dans des organisations à but non lucratif et dans la fonction publique (par exemple en tant qu’animateurs de colonies de vacances, employés d’un jardin communautaire ou assistants administratifs). Aux États-Unis, cela faisait des décennies que des programmes pour l’emploi des jeunes similaires à OSC+ étaient utilisés pour faire face à des problèmes comme le fort taux de chômage et de criminalité chez les jeunes. Cependant, il n’existait que peu de preuves scientifiques de leur efficacité (Gelber et al., 2014).
Une évaluation aléatoire de la cohorte 2012 du programme OSC+ a révélé qu’il avait entraîné une réduction de 43 % des arrestations pour crimes violents chez les jeunes ayant reçu une offre d’emploi d’été (Heller, 2014). Prouver l’efficacité d’un programme peut aider à justifier la nécessité de consacrer des ressources à son expansion. En 2015, la SARL Inner City Youth Empowerment a ainsi fait don à la ville de Chicago des fonds nécessaires pour étendre le programme OSC+ afin d’en doubler le nombre de bénéficiaires, citant les résultats de l’évaluation comme facteur déterminant dans leur décision d’investir dans le programme.5
Les chercheurs peuvent également avoir recours à des protocoles de recherche sur mesure pour étudier les effets d’un programme déjà en place, et utiliser les résultats obtenus pour mieux comprendre l’impact du programme ou en affiner la conception. Par exemple, l’extension d’OSC+ a permis à la ville de Chicago et aux chercheurs de s’appuyer sur l’évaluation initiale afin de déterminer si les effets du programme variaient entre différents sous-groupes, par exemple entre les étudiants de sexe masculin et de sexe féminin, ou entre les étudiants d’origine latino-américaine et les autres.
Souvent, les chercheurs peuvent également profiter de la phase de déploiement pour en apprendre davantage sur les mécanismes clés qui génèrent l’impact du programme. Pour ce faire, ils peuvent avoir recours à des protocoles de recherche comme la randomisation échelonnée (le traitement est progressivement étendu à différentes sections de l’échantillon sélectionnées aléatoirement) ou bien, si le taux de participation initial est faible, les méthodes de randomisation avec encouragements (certains individus sont sélectionnés aléatoirement pour recevoir des encouragements ou de l’aide pour participer au programme). Évaluer un programme pendant sa phase de déploiement peut être l’occasion d’en perfectionner les modalités en testant plusieurs variantes de certaines de ses composantes. Si certains modèles du programme (ou le programme dans son ensemble) s’avèrent moins efficaces que prévu, les responsables peuvent alors décider de consacrer leurs ressources à d’autres modèles plus performants. Pour plus d’informations sur les différentes méthodes de randomisation qui exploitent le processus naturel d’expansion ou de déploiement d’un programme, consultez notre présentation intitulée How to Randomize.
Il est important de noter que toute évaluation aléatoire doit reposer sur un échantillon de taille suffisante pour lui permettre de détecter l’impact éventuel du programme. Si l’échantillon est trop réduit, les fluctuations naturelles de la variable de résultat étudiée risquent de ne pas nous permettre de mesurer l’impact de l’intervention de façon concluante : il sera alors impossible de déterminer si les différences entre le groupe de traitement et le groupe témoin sont due à l’intervention ou si elles sont le fruit du hasard. Réaliser une évaluation aléatoire dans de telles conditions reviendrait à faire peser des contraintes inutiles sur les participants de l’étude et à utiliser des ressources qui pourraient être employées ailleurs de façon plus productive. Pour plus d’informations, veuillez vous reporter à la ressource de J-PAL North America sur les risques inhérents aux évaluations qui manquent de puissance statistique.
De même, il est essentiel de savoir si les résultats de l’évaluation aléatoire vont réellement permettre de modifier la façon dont les politiques sont élaborées ou dont le programme est mis en œuvre. Si ce n’est pas le cas, ou si les enseignements que l’on peut espérer en tirer ne justifient pas l’investissement requis, il n’est peut-être pas raisonnable de procéder à une telle évaluation. Par exemple, si le coût de la collecte de données est tellement élevé qu’il utilise la majeure partie du budget du programme, ou si l’évaluation prend tellement de temps que le programme lui-même risque de se terminer avant que l’on obtienne les résultats, il n’est peut-être pas utile de procéder à une évaluation (à moins que les résultats puissent également servir de base à de futurs programmes). Cette remarque est en lien étroit avec les considérations sur l’éthique de la recherche présentées plus bas : une étude ne doit être entreprise que si les avantages qu’elle représente l’emportent sur les coûts engendrés.
Pour en savoir plus sur les programmes PROGRESA, Raskin et OSC+, voir ci-dessous




Les défis de la randomisation dans le monde réel
Si les évaluations aléatoires peuvent être d’excellents outils pour étudier l’impact d’une politique ou d’un programme, elles ne sont pas pour autant adaptées à toutes les situations. Dans les exemples qui suivent, un protocole de recherche bien pensé permet souvent de contourner les difficultés liées à la randomisation, mais il arrive aussi que l’évaluation aléatoire ne soit tout simplement pas une solution adaptée. Pour plus d’informations, voir également le guide de J-PAL North America intitulé « Real-World Challenges to Randomization » ou notre conférence « How to Randomize » (présentation disponible ci-dessous).

La politique affecte un groupe très important, voire le pays entier
La randomisation s’avère plus complexe lorsque le programme concerne un groupe très nombreux. À l’extrémité du spectre, on trouve les politiques mises en œuvre de façon centralisée au niveau national, voire supranational, comme par exemple une politique monétaire visant à réglementer la masse monétaire. Dans ce cas, la randomisation n’est pas possible car l’échantillon est constitué d’une seule entité – le pays où se situe la banque centrale qui met en place la politique – et il n’existe pas de scénario contrefactuel dans lequel une politique différente serait mise en place. De même, on ne peut pas utiliser la randomisation pour connaître l’impact d’un événement historique ou d’un phénomène naturel particulier, comme un changement de gouvernement ou un tremblement de terre (et il serait très difficile de construire un contrefactuel crédible pour ce type de politiques ou d’événements : à ce sujet, voir également la section ci-dessous sur les autres méthodes d’évaluation).
Même à plus petite échelle, une intervention peut encore toucher un très grand nombre de personnes à la fois, ou avoir des retombées indirectes, ou effets de diffusion, sur des tiers. On parle d’effets de diffusion lorsque le traitement a non seulement un impact direct sur ceux qui en bénéficient, mais aussi un impact indirect sur d’autres individus. Par exemple, au sein d’une communauté très soudée, les subventions en espèces ou les prêts accordés à certains ménages finissent souvent par atteindre d’autres membres de la communauté sous forme de cadeaux ou de prêts de la part du ménage d’origine. Ces effets peuvent se manifester dans de nombreux domaines des politiques sociales, qu’il s’agisse de l’environnement (par exemple, une diminution du taux d’asthme dans l’ensemble de la population lorsque certains se chauffent avec des combustibles plus propres), du marché du travail (par exemple, une concurrence plus intense sur le marché du travail lorsque certaines personnes bénéficient d’une meilleure formation), ou encore des subventions alimentaires pour les populations défavorisées (par exemple, des ménages qui accueillent d’autres membres de leur famille).
Les effets de diffusion peuvent compliquer la mise en œuvre d’une évaluation d’impact, car le traitement risque alors d’affecter indirectement le groupe témoin. Dans de nombreux cas, une évaluation aléatoire dotée d’un bon protocole de recherche peut suffire à résoudre ce problème, la solution consistant généralement à augmenter le niveau de randomisation : on randomise par exemple l’intervention non pas au niveau des ménages, mais au niveau de la communauté (voir ci-dessous). Cependant, il arrive que la prise en compte de ces problèmes rende la mise en place d’une évaluation aléatoire trop difficile ou trop coûteuse. Notons que ce défi est commun à toutes les formes d’évaluation d’impact : si le groupe témoin est « contaminé » par le groupe de traitement, il est impossible d’obtenir une mesure non biaisée de l’impact.
La randomisation est impossible
Certaines choses ne se prêtent tout simplement pas à l’assignation aléatoire. Par exemple, on ne peut pas avoir recours à une évaluation aléatoire pour mesurer l’impact du sexe sur les résultats scolaires : en effet, il n’est pas possible d’utiliser la randomisation pour déterminer comment une personne par ailleurs « identique » aurait réussi à l’école si elle avait été d’un autre sexe. D’ailleurs, nombreux sont ceux qui affirment que l’hypothèse même d’un tel contrefactuel n’a pas de sens : comment une personne pourrait-elle être « identique » mais d’un sexe différent ? (Angrist & Pischke, 2009). Encore une fois, ce problème n’est pas spécifique aux méthodes d’estimation de l’impact fondées sur la randomisation ; Angrist et Pischke font ainsi valoir ce point pour n’importe quel type d’estimation de la causalité.
Notons que cela n’empêche pas d’avoir recours aux évaluations aléatoires pour étudier les discriminations : des chercheurs affiliés à J-PAL ont par exemple mené des études consistant à créer des CV fictifs où seul le nom du candidat variait pour suggérer un sexe donné ou une origine ethnique particulière, puis à mesurer le taux de réponse des employeurs et le nombre de convocations à des entretiens.6 [!7] En outre, les évaluations aléatoires peuvent évidemment être utilisées pour étudier l’impact des politiques visant à renforcer l’autonomie des femmes. Le secteur Genre de J-PAL traite de ces questions.
Considérations éthiques
Les principes éthiques de la recherche exigent qu’une étude impliquant des participants humains soit conçue de façon à en maximiser les effets bénéfiques tout en minimisant les risques pour les participants. Les chercheurs doivent également réfléchir soigneusement à tous les risques que la recherche peut présenter pour les non-participants, notamment le personnel ou les membres de la communauté. Une ressource détaillée sur les règles éthiques applicables aux évaluations aléatoires est disponible ici : Principes éthiques pour les évaluations aléatoires.
Il arrive parfois que des problèmes éthiques liés au fait de faire bénéficier un groupe de traitement d’une intervention ou d’en priver un groupe témoin empêche la réalisation d’une évaluation aléatoire. Par exemple, il est largement admis que l’on ne doit pas avoir recours à une évaluation aléatoire pour tester les effets de prestations que tous les membres de la population cible sont en droit de recevoir. Dans ce cas, il serait contraire à l’éthique de créer un groupe témoin que l’on empêcherait de bénéficier de l’intervention, et ce même si le fait de mener une évaluation aléatoire permettrait d’obtenir des informations précieuses. De la même manière, les chercheurs ne peuvent pas tester des interventions qui ont de fortes chances d’être préjudiciables.
Une modification du protocole de recherche de l’étude peut contribuer à répondre à ces préoccupations. Il est notamment possible de mener une évaluation aléatoire sans restreindre l’accès à l’intervention. Par exemple, comme nous l’avons évoqué plus haut, on peut sélectionner aléatoirement certains individus pour les inciter à participer au programme, par exemple en leur envoyant des e-mails de rappel ou en leur téléphonant, sans pour autant refuser l’accès aux autres participants intéressés par l’intervention. Dans d’autres cas, il peut être intéressant de comparer deux versions différentes d’une même intervention, par exemple une version déjà existante et une version à laquelle une nouvelle composante a été ajoutée.
Les chercheurs et le personnel de J-PAL évaluent soigneusement les critères éthiques lorsqu’ils envisagent de mettre en œuvre une étude, et chaque évaluation financée ou réalisée par J-PAL est soumise à l’avis d’un comité d’éthique officiel, ou Institutional Review Board (IRB), dont la mission est de protéger les droits et le bien-être des participants à l’étude.
Autres méthodes d’évaluation d’impact
Tous les types d’évaluation quantitative de l’impact estiment l’efficacité du programme étudié en comparant la situation des bénéficiaires (individus, communautés, écoles, etc.) qui ont participé au programme par rapport à ceux qui n’y ont pas participé. La principale distinction entre les différentes méthodes réside dans le mode de sélection des groupes test et témoin. Il peut par exemple s’agir du même groupe de participants, mais à des moments différents (comparaison avant-après), ou d’individus qui se situent juste au-dessus ou juste en dessous d’un certain seuil d’éligibilité pour un programme donné (modèle de régression sur discontinuité).
L’un des principaux défis des études non randomisées consiste à éliminer les différences systématiques entre les participants et les non-participants : c’est le problème de sélection décrit plus haut. Chacune des méthodes non expérimentales repose sur un ensemble d’hypothèses qui permettent d’établir la comparabilité du groupe de traitement et du groupe témoin. Lorsque ces hypothèses sont vérifiées, le résultat de l’évaluation est non biaisé. Il est essentiel de vérifier que les hypothèses sont respectées dans chaque cas particulier.
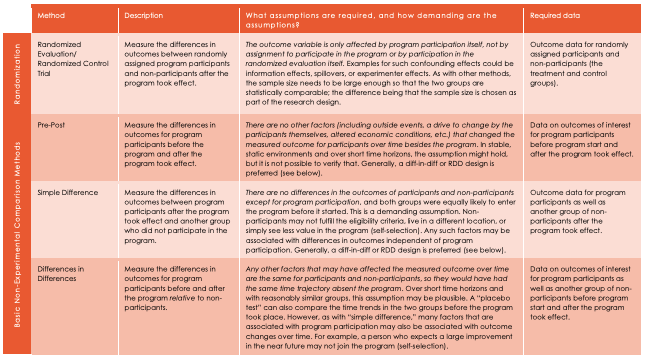
Un tableau tiré de nos études de cas (voir ci-dessous) recense les méthodes d'évaluation les plus répandues et les hypothèses sur lesquelles elles reposent. Si la randomisation est un outil efficace pour éliminer les biais de sélection, les études non randomisées peuvent s’avérer précieuses dans les contextes où il est impossible de réaliser une évaluation aléatoire (voir ci-dessus).
FAQs
Pour en savoir plus sur l’approche de J-PAL, nous vous invitons à consulter la page Nous connaître de notre site Internet. Par ailleurs, les protocoles que nous avons mis en place pour garantir l’éthique de la recherche sont décrits plus en détail dans notre ressource Principes éthiques pour les évaluations aléatoires. En outre, le guide de J-PAL North America intitulé Common questions and concerns about randomized evaluations aborde les questions les plus fréquentes au sujet des évaluations aléatoires, également reproduites ci-dessous.
Quels sont les protocoles mis en place par J-PAL pour garantir l’éthique de la recherche ?
J-PAL œuvre pour faire reculer la pauvreté en veillant à ce que les politiques sociales s’appuient sur des preuves scientifiques, et aspire à ce que les recherches menées en son sein soient, à terme, utiles aux communautés qui y participent. L’éthique de la recherche est donc au cœur de la mission de J-PAL, et il est de la plus haute importance que chaque étude soit menée dans le respect des principes éthiques, du début jusqu’à la fin. Notre ressource sur l’éthique contient des conseils pratiques plus détaillés sur les principes éthiques dont il faut tenir compte lors de la conception et de la mise en œuvre d’un projet de recherche.
Afin de garantir le respect de l’éthique dans les études qu’il met en œuvre et finance, J-PAL a mis en application ces conseils en adoptant un certain nombre de mesures proactives dans l’ensemble de ses bureaux. Ces mesures sont en premier lieu les exigences intégrées à nos protocoles de recherche, qui doivent être respectées dans le cadre de chaque projet financé ou mis en œuvre par J-PAL. Les projets menés par les bureaux de J-PAL font l’objet d’audits réguliers afin de contrôler le respect de ces protocoles. Parmi les autres mesures, citons notamment la formation à l’éthique du personnel de recherche, la formation approfondie sur le consentement éclairé et les accords de confidentialité dispensée aux enquêteurs, des exigences strictes en matière de sécurité des données pour protéger les données personnelles des participants à chaque étape du cycle de vie du projet, et la mise en place de comités d’éthique officiels, ou IRB, en collaboration avec les institutions locales. Pour plus d’informations sur ces mesures, voir la section « Éthique et recherche chez J-PAL » dans notre ressource sur l’éthique.
Est-il éthique d’assigner des individus à un groupe témoin, les empêchant ainsi potentiellement d’avoir accès à une intervention précieuse ?
Comme nous l’avons expliqué plus haut dans la section intitulée « Les défis de la randomisation dans le monde réel », certains cas ne se prêtent pas à la réalisation d’un essai contrôlé randomisé (ECR). S’il existe des preuves rigoureuses de l’efficacité d’une intervention et que des ressources suffisantes sont disponibles pour en faire bénéficier tout le monde, il serait contraire à l’éthique d’empêcher certaines personnes d’y avoir accès. Cependant, dans de nombreux cas, on ignore si l’intervention est efficace (il est possible qu’elle soit néfaste) ou si les ressources disponibles sont suffisantes pour en faire bénéficier tout le monde. Dans ces conditions, non seulement l’évaluation aléatoire est éthique, mais elle peut produire des données probantes qui permettront de généraliser l’intervention si elle se révèle efficace, ou à l’inverse de réaffecter les ressources qui lui étaient consacrées si elle s’avère inefficace.
Lorsqu’un programme est déployé pour la première fois, ou que le nombre de participants est supérieur au nombre de places disponibles, des contraintes financières et logistiques peuvent empêcher l’organisme d’en faire bénéficier tout le monde. Dans ce cas, la randomisation peut constituer un mode de sélection plus équitable que d’autres (comme le principe du premier arrivé, premier servi) pour choisir les individus qui vont avoir accès au programme. La mise en œuvre d’une évaluation aléatoire peut modifier le processus de sélection, mais pas le nombre de bénéficiaires.
Il est également possible de mener une évaluation aléatoire sans restreindre l’accès à l’intervention. On peut notamment sélectionner aléatoirement certains participants pour les inciter à s’inscrire au programme, sans pour autant refuser l’accès aux autres participants intéressés par l’intervention. Dans d’autres cas, il peut être utile de comparer deux versions différentes d'une même intervention, par exemple une version déjà existante et une version à laquelle on a ajouté une nouvelle composante.
Est-il possible de réaliser une évaluation aléatoire à faible coût sans avoir à attendre des années pour en obtenir les résultats ?
Si la collecte de données d’enquête originales est souvent la partie la plus coûteuse d’une évaluation, ce problème ne concerne pas uniquement les évaluations aléatoires. En outre, il est de plus en plus souvent possible de réaliser des évaluations à un coût relativement faible en mesurant les variables de résultat sur la base de données administratives existantes plutôt que de collecter des données d’enquête.
Quant au temps nécessaire pour mesurer l’impact d’une intervention, il dépend en grande partie des variables de résultat étudiées. Ainsi, les effets à long terme d’une intervention éducative (sur les revenus et l’emploi, par exemple) nécessitent une étude plus longue que l’analyse de ses effets à court terme, notamment sur les notes d’examen, qui peuvent être obtenues en consultant des dossiers administratifs.
Enfin, il faut évaluer le temps et les dépenses nécessaires à la réalisation d’une évaluation aléatoire au regard de la valeur des données factuelles qu’elle permettrait de recueillir et du coût à long terme que représenterait la poursuite d’une intervention dont on ignore le degré d’efficacité.
Une évaluation aléatoire peut-elle permettre de déterminer non seulement si une intervention a fonctionné, mais aussi comment et pourquoi ?
Lorsqu’elles sont conçues et mises en œuvre correctement, les évaluations aléatoires peuvent non seulement nous dire si une intervention a été efficace, mais aussi répondre à un certain nombre d’autres questions pertinentes pour l’élaboration de politiques publiques. Elles peuvent par exemple tester différentes versions d’une intervention afin d’identifier les composantes qui sont nécessaires à son efficacité, fournir des informations sur les résultats intermédiaires pour évaluer la théorie du changement sur laquelle repose l’intervention, ou encore comparer l’effet d’une intervention sur différents sous-groupes.
Toutefois, comme toute autre étude, les évaluations aléatoires ne constituent qu’une pièce d’un puzzle plus vaste. Pour parvenir à une compréhension véritablement fine de l’impact d’une intervention, il faut recouper les résultats d’une ou plusieurs évaluations aléatoires avec la théorie économique, des données descriptives et des connaissances locales.
Les résultats des évaluations aléatoires sont-ils généralisables à d’autres contextes ?
Le problème de la généralisation est commun à toute évaluation d’impact qui teste une intervention spécifique dans un contexte spécifique. Une évaluation aléatoire correctement conçue et mise en œuvre présente toutefois le net avantage, par rapport aux autres méthodes d’évaluation d’impact, de garantir que l’impact estimé d’une intervention dans son contexte d’origine n’est pas biaisé.
En outre, l’évaluation aléatoire peut être conçue de façon à tenir compte de la question de la généralisation du programme. Elle peut ainsi tester l’intervention dans différents contextes, ou tester la reproduction d’une intervention fondée sur des données probantes dans un nouveau contexte. En s’appuyant à la fois sur une théorie du changement qui décrit les conditions nécessaires à la réussite de l’intervention et sur une bonne connaissance des conditions locales dans chaque nouveau contexte, on peut également améliorer la reproductibilité de l’intervention et faire en sorte de pouvoir en tirer des enseignements plus généraux
Dernière modification : avril 2021.
Ces ressources sont le fruit d’un travail collaboratif. Si vous constatez un dysfonctionnement, ou si vous souhaitez suggérer l’ajout de nouveaux contenus, veuillez remplir ce formulaire.
Ce document a été traduit de l’anglais par Marion Beaujard.
Acknowledgments
Nous remercions Rohit Naimpally pour ses commentaires précieux. Ce document a été relu et corrigé par Evan Williams, et traduit de l’anglais par Marion Beaujard. Toute erreur est de notre fait.
1.
Banerjee, Abhijit, Rema Hanna, Jordan Kyle, Benjamin A. Olken, and Sudarno Sumarto, 2018. “Tangible Information and Citizen Empowerment: Identification Cards and Food Subsidy Programs in Indonesia.” Journal of Political Economy 126 (2): 451-491.
2.
Des considérations similaires se posent avec de nombreux programmes visant à compléter, remplacer ou renforcer l'alimentation et les boissons habituelles des ménages, qu'il s'agisse de l'enrichissement en fer et en iode ou de la chloration de l'eau : les habitudes et les préférences alimentaires sont puissantes et difficiles à modifier.
3.
Voir Bougen et al.’s (2018) Using RCTs to Estimate Long-Run Impacts in Development Economics pour une discussion sur les types d'évaluations randomisées les mieux adaptés à la mesure des effets à long terme.
4.
Le programme TUP, lancé par BRAC au Bangladesh, est une approche multifacette de réduction de la pauvreté dans laquelle les ménages reçoivent un actif productif (généralement du bétail), des allocations alimentaires hebdomadaires, ainsi qu'une formation sur l'augmentation de la productivité de cet actif. Pour plus d'informations, voir Banerjee et al. (2020).
6.
Behaghel, Luc, Bruno Crepon, and Thomas Le Barbanchon. 2014. “Unintended Effects of Anonymous Resumes”. IZA Discussion Paper Series no. 8517.
7.
Bertrand, Marianne, and Sendhil Mullainathan. 2004. “Are Emily and Greg More Employable than Lakisha and Jamal? A Field Experiment on Labor Market Discrimination”
Additional Resources
Resources
J-PAL’s Table of Estimation Methods
J-PAL North America’s Real World Challenges to Randomization
References
Angrist, Joshua and Pischke, Jorn-Steffen. 2009. Mostly Harmless Econometrics: An Empiricist's Companion. 1 ed., Princeton University Press
Banerjee, Abhijit, Rema Hanna, Jordan Kyle, Benjamin A. Olken, and Sudarno Sumarto. 2018. “Tangible Information and Citizen Empowerment: Identification Cards and Food Subsidy Programs in Indonesia.” Journal of Political Economy 126 (2): 451-491. https://doi.org/10.1086/696226
Banerjee, Abhijit, Esther Duflo, and Garima Sharima. 2020. “Long-term Effects of the Targeting the Ultra Poor Program.” NBER Working Paper 28074. DOI 10.3386/w28074
Bates, Mary Ann and Glennerster, Rachel, 2017. “The Generalizability Puzzle”. Stanford Social Innovation Review, https://ssir.org/articles/entry/the_generalizability_puzzle
Behagel, Luc, Bruno Crépon, and Thomas Le Barbanchon. 2014. "Unintended Effects of Anonymous Resumes" IZA Discussion Paper Series No. 8517
Behrman, James. 2007. "Policy-Oriented Research Impact Assessment (PORIA) Case Study on the International Food Policy Research Institute (IFPRI) and the Mexican PROGRESA Anti-Poverty and Human Resource Investment Conditional Cash Transfer Program" International Food Policy Research Institute.
Bertrand, Marianne and Sendhil Mullainathan. 2004. "Are Emily And Greg More Employable Than Lakisha And Jamal? A Field Experiment On Labor Market Discrimination." American Economic Review 94(4): 991-1013. https://doi.or/10.1257/0002828042002561
Chetty, Raj, Nathaniel Hendren, and Lawrence F. Katz. 2016. "The Effects of Exposure to Better Neighborhoods on Children: New Evidence from the Moving to Opportunity Experiment." American Economic Review, 106 (4): 855-902. DOI: 10.1257/aer.20150572
Cunha, Jesse M., Giacomo De Giorgi, and Seema Jayachandran. 2019. “The Price Effects of Cash Versus In-Kind Transfers”. The Review of Economic Studies, 86(1):240–281. https://doi.org/10.1093/restud/rdy018
Gelber, Alexander, Adam Isen and Judd B. Kessler. 2016. "The Effects of Youth Employment - Evidence from New York City Summer Youth Employment Program Lotteries." Quarterly Journal of Economics 131 (1): 423-460. https://doi.org/10.1093/qje/qjv034
Duflo, Esther, Pascaline Dupas, and Michael Kremer. 2011. “Peer Effects, Teacher Incentives, and the Impact of Tracking: Evidence from a Randomized Evaluation in Kenya.” American Economic Review 101 (5): 1739-74.
Duflo, Esther, Pascaline Dupas, and Michael Kremer. 2014. “School Governance, Teacher Incentives, and Pupil-teacher Ratios: Experimental Evidence from Kenyan Primary Schools.” Journal of Public Economics 123 (15): 92-110.
Finkelstein, Amy, Yunan Ji, and Neale Mahony. 2018. “Mandatory Medicare Bundled Payment Program for Lower Extremity Joint Replacement and Discharge to Institutional Postacute Care: Interim Analysis of the First Year of a 5-Year Randomized Trial” JAMA, 320(9): 892-900 doi:10.1001/jama.2018.12346
Gertler, Paul J and Simone Boyce. 2003. "An Experiment in Incentive-Based Welfare: The Impact of PROGRESA on Health in Mexico," Royal Economic Society Annual Conference 2003 85, Royal Economic Society. RePEc:ecj:ac2003:85
Heller, Sara. 2014. "Summer Jobs Reduce Violence among Disadvantaged Youth" Science Magazie 346(5): 1219-1223. http://dx.doi.org/10.1126/science.1257809
J-PAL. 2019. “Case Study: Extra Teacher Program: How to Randomize.” Abdul Latif Jameel Poverty Action Lab. 2019. Cambridge, MA.
J-PAL. “Case Study: Cognitive Behavioral Therapy in Chicago Schools: Theory of Change and Measuring Outcomes.” Abdul Latif Jameel Poverty Action Lab. 2019. Cambridge, MA.
J-PAL. “Case Study: Get Out the Vote: Why Randomize?” Abdul Latif Jameel Poverty Action Lab. 2019. Cambridge, MA.
J-PAL. “Deworming in Kenya: Threats and Analysis.” Abdul Latif Jameel Poverty Action Lab. 2019. Cambridge, MA
J-PAL. The Generalizability Puzzle. Delivered in J-PAL Global & North America’s 2019 Evaluating Social Programs course.
Katz, Lawrence, F., Jeffrey R. Kling, and Jeffrey B. Liebman. 2001. “Moving to Opportunity in Boston: Early Results of a Randomized Mobility Experiment.” The Quarterly Journal of Economics 116(2)607–654. https://doi.org/10.1162/00335530151144113
Lamanna, Francesca. 2014. "A Model from Mexico for the World." The World Bank.
Sacarny, Adam, David Yokum, Amy Finkelstein, and Shantanu Agrawal. 2016. “Medicare Letters to Curb Overprescribing of Controlled Substances Had No Detectable Effect on Providers”. Health Affairs, 35(3). https://doi.org/10.1377/hlthaff.2015.102